以前youtubeのVstoneチャンネルに、くるみちゃんを使ってChat-GPTによる会話を行うでも動画をアップロードしました。これに関する技術的な背景は、以下の過去記事内に簡単にまとめて紹介しております。
https://vstone.co.jp/robotshop/blog/archives/7493
今回はこれを応用して、デベロッパ版Sota(edison版)にて、同様にChat-GPTを用いた会話デモを実装してみたいと思います。とりあえず今回は導入編として、Chat-GPTの軽い体験とSDKを使ってチャットの基礎部分を作成してみます。
ちなみに、本記事では説明をわかりやすくするため、「SotaをChat-GPTで会話させる」等のように、対話AI機能を「Chat-GPT」と呼称していますが、厳密にはOpenAIが提供しているChatAPI機能を用いた対話であり、Chat-GPTとしてサービス提供されているAIと必ずしも同水準の会話が得られるわけではない点についてご留意ください。
また、OpenAIのChatAPIは利用回数等に応じた費用が発生する場合があります(2023年8月現在では、チャット機能の利用にはクレジットカードの支払い情報登録が必須のようです)。あらかじめ支払いに利用できるクレジット―カード情報も準備しておいてください。
Chat-GPTを体験してみる
まず、何はなくともChat-GPTのAPIを利用できるようにするために、OpenAIのアカウント登録をする必要があります。
OpenAIのアカウントは、下記URLにアクセスし、「Sign up」を選びます。
https://chat.openai.com/auth/login

アカウントを作成してログインすると、早速ChatGPTによる対話を体験できます。
画面左上の「+New chat」をクリックし、画面下に表示される「Send a message」に適当な文言を入力すると、AIとの対話を始められます。
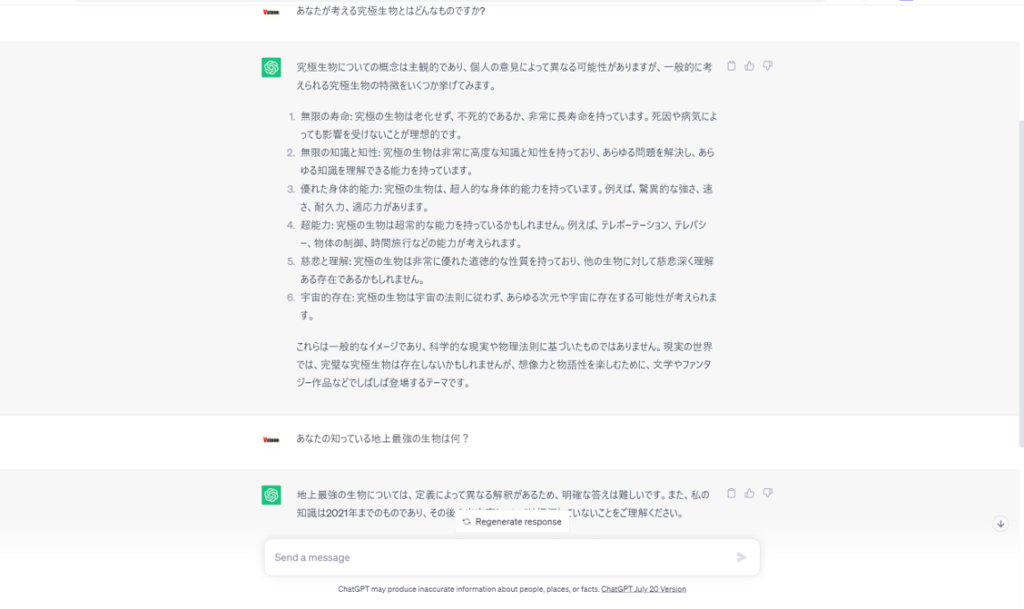
どうやらChat-GPTは柱の男及び範馬の血筋についての知識は持ち合わせていないらしい
支払い設定を行い、PlayGroundを使ってみる
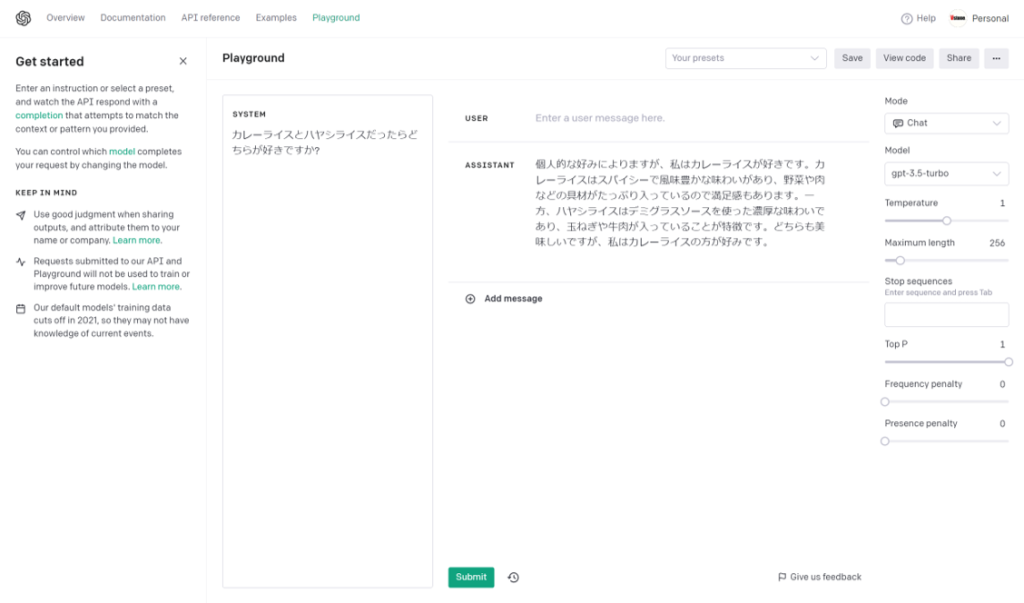
OpenAIのページではplaygroundという機能が提供されており、APIを用いた実装を行う前に、パラメータのチューニングについてある程度確認できるようになっています。
playgroundへは、以下のURLにアクセスします(画面上メニューの「Playground」からも入れます)。
https://platform.openai.com/playground
とりあえず、画面中央のSYSTEM欄に適当な文言を入力しsubmitをクリックすると、先ほどの対話デモのように返答が自動的に返されます。
この返答を生成するためのAIの設定が、画面右側に表示されたエリアになります。
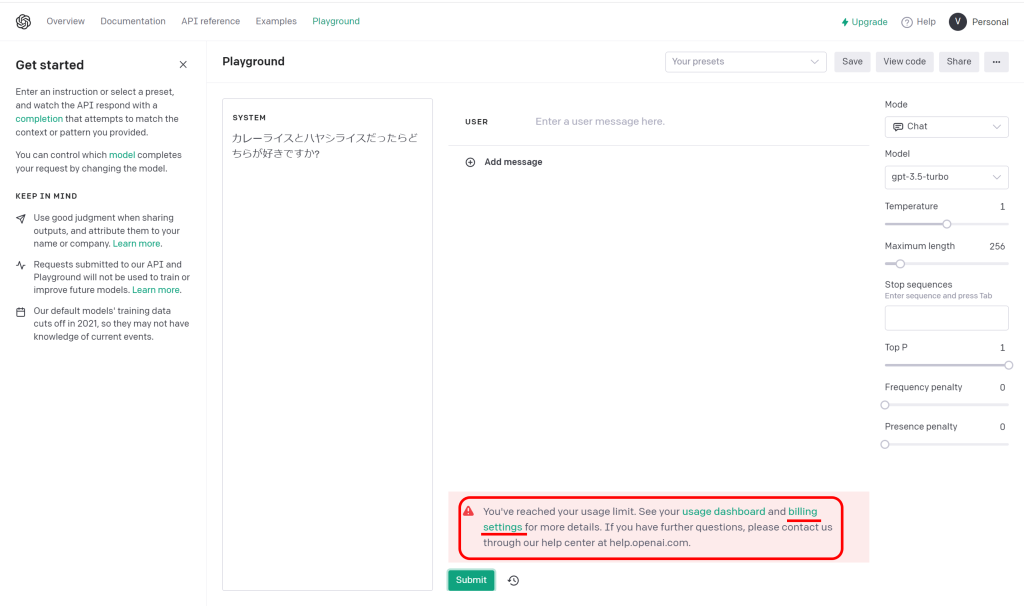
なお、submitをクリックして「You’ve reached your usage limit. See your usage dashboard and billing settings for more details. If you have further questions, please contact us through our help center at help.openai.com.」というエラーが表示された場合、APIの機能を利用するための支払い設定が必要です。「billing settings」のリンクをクリックして、支払い情報を設定してください。
APIキー・組織キーを取得する
ひとしきり遊んだところで、アプリ開発へ移っていきます。APIの設定情報を生成します。
APIを利用するためにはAPIキー(API Key)と組織キー(Organization Key)の二つの情報が必要になります。
ログイン後、右上の「Personal」から「View API keys」をクリックします。
https://platform.openai.com/overview
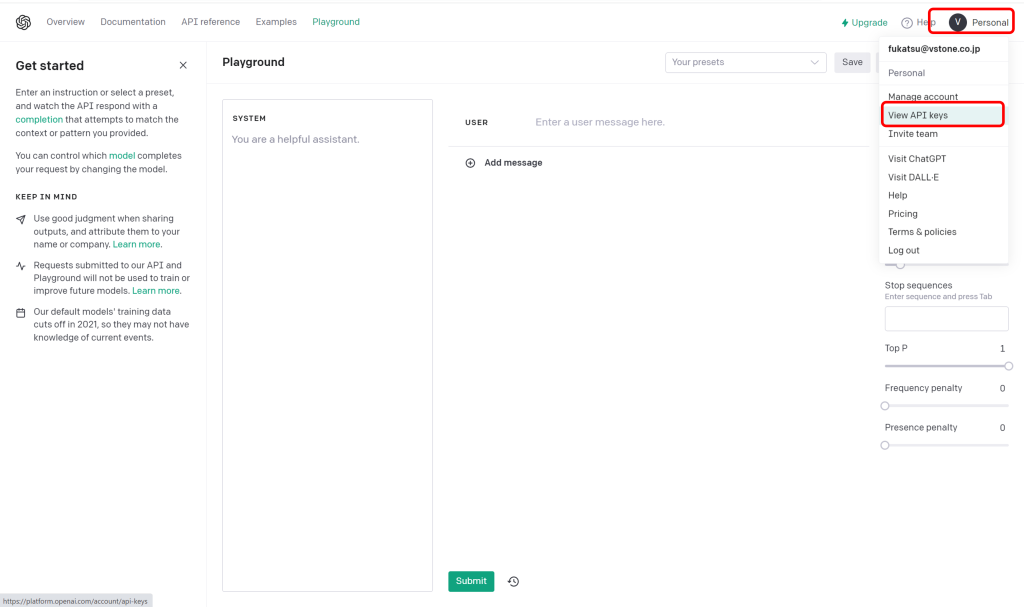
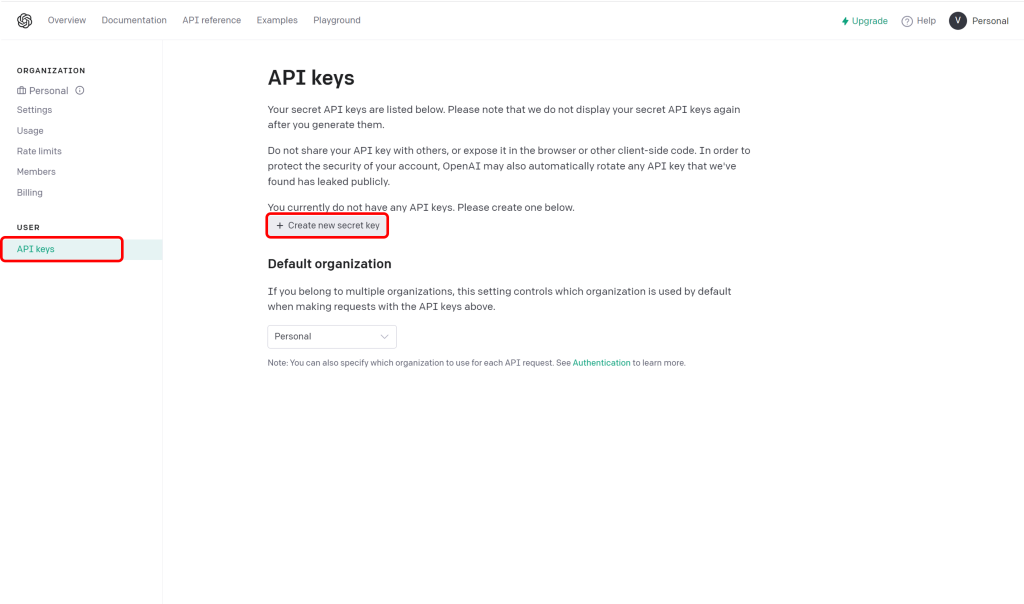
APIキーを作ります。「+Create new secret key」をクリックして新しいAPIキーを発行してください。
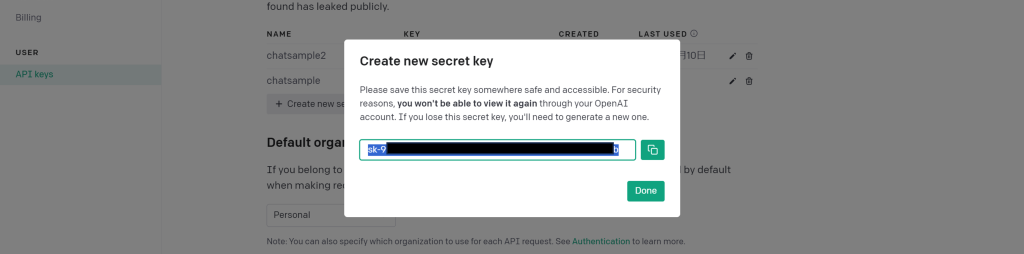
APIキーは「sk-xxxxx」のようにsk-で始まる文字列です。一度表示された後は、再度確認することができないので、必ずどこかにメモしておいてください(メモし忘れたら、作成したキーを削除して別のキーを作り直してください)。
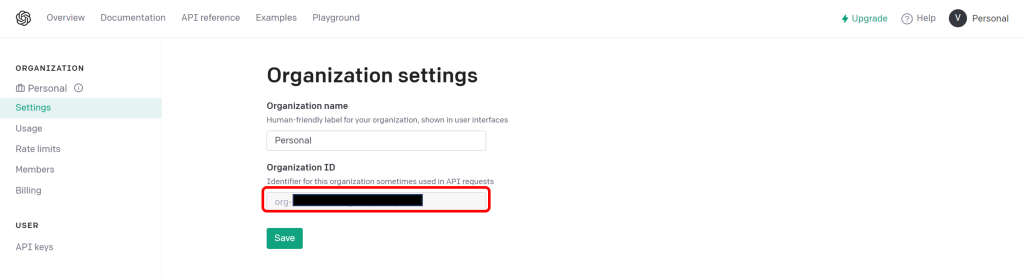
続いてOrganizationKeyを確認します。settingページ内の「Organization settings」の項目で確認でき、「org-xxxxx」のようにorg-から始まる文字列です。
※APIキーと組織キーを利用することで、第三者でもチャットAPIを利用できる状態になるため、これらの情報は外部に漏れないように厳重に管理し、不要になったらキーを削除するなどするようにしてください。
開発環境の構築(Windowsの場合)
node/npmをインストールします。下記のwebページよりWindows版のインストーラをダウンロードしてインストールします(2023年7月現在、18.17.0 LTSのインストールが推奨されています)。
https://nodejs.org/en
下記blog記事なども参考になると思います。
https://qiita.com/taiponrock/items/9001ae194571feb63a5e
インストールしたら、任意のフォルダにプロジェクトを作成してプログラムを作成していきます。
適当なフォルダを作成し、コマンドプロンプトでそのフォルダを開いて、npm initと入力します。
入力するとプロジェクトの新規作成を開始するので、適当に項目を入力していきます。基本的にはpackageに適当な名前(chatsample等)を入力し、それ以外はそのままenterキーを入力していくだけでOKです。
> npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help init` for definitive documentation on these fields
and exactly what they do.
Use `npm install <pkg>` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (npmtest) chatsample
version: (1.0.0)
description:
entry point: (index.js)
test command:
git repository:
keywords:
author:
license: (ISC)
About to write to C:\Users\fukat\Documents\npmtest\package.json:
{
"name": "chatsample",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
Is this OK? (yes) yes
続いてOpenAIのライブラリをインストールします。
> npm install openai
expressをインストールします。
> npm install express
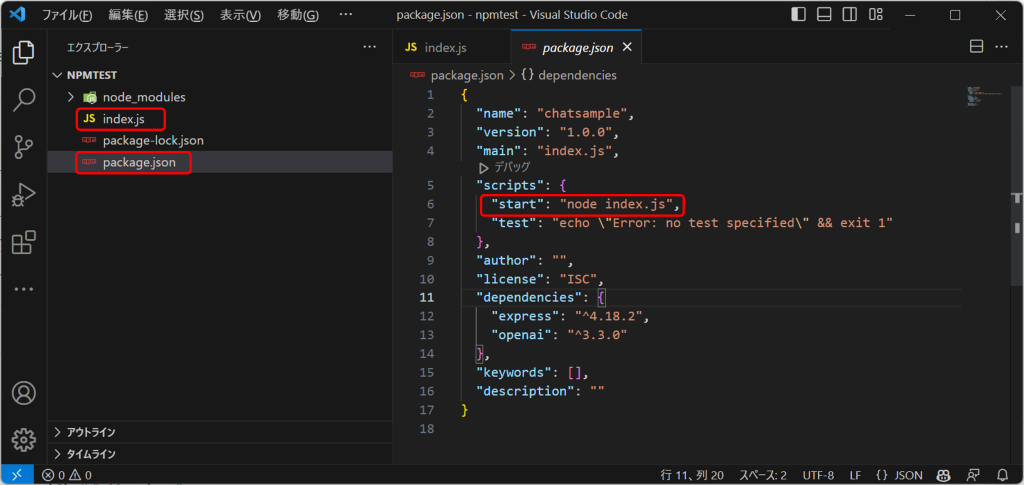
また、プロジェクトにはソースファイルが一つも存在しないので、index.jsというファイルを作成します。併せて、実行設定として、package.jsonの scripts:{}の中に"start": "node index.js",という行を追加します。
{
...
"scripts": {
"start": "node index.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
...
}
コードの作成
続いて、index.jsをテキストエディタで開いて、以下のソースを入力します。
API_KEYとORG_KEYの部分は、先ほど取得した情報にそれぞれ置き換えてください。
const express = require('express');
const { Configuration, OpenAIApi } = require("openai");
// 最も有能なGPT-3モデル
const MODEL_DAVINCI = "text-davinci-003";
// 非常に有能で、Davinciよりも高速
const MODEL_CURIE = "text-curie-001";
// 簡単なタスク、非常に高速
const MODEL_BABBAGE = "text-babbage-001";
// 非常に単純なタスクが可能で、最速
const MODEL_ADA = "text-ada-001";
const MODEL = MODEL_DAVINCI;
const MAX_TOKENS=300;
// OpenAIのAPIキー
const API_KEY = 'sk-************************************';
// OpenAIのOrganizationキー
const ORG_KEY = 'org-************************';
// OpenAIの初期化
const configuration = new Configuration({
apiKey: API_KEY,
organization: ORG_KEY,
});
const openai = new OpenAIApi(configuration);
// リクエストPOSTイベント
function postevent(request, response) {
// リクエストデータを受信し蓄積していく
let body = '';
request.on('data', function(data) {
// dataイベントでデータを受信したらbodyに追加していく
body += data;
});
// リクエスト終了時のイベント。
request.on('end', function() {
// endイベントがきたらbodyをパースしてオブジェクトにする
console.log(body);
let jsonData = JSON.parse(body);
console.log(jsonData);
// リクエストデータが存在しない場合
if(!jsonData || !("text" in jsonData)) {
response.writeHead(400);
response.end();
return;
}
// チャット処理を呼び出す
requestChatGPT(jsonData.text, Number(MAX_TOKENS), MODEL, jsonData.stoped, (data)=>{
console.log(data);
let resData = new Object();
resData.text = data.choices[0].text;
let jsonData = JSON.stringify(resData);
response.writeHead(200);
response.end(jsonData);
}, (err)=>{
console.error(err);
response.writeHead(500);
response.end();
});
});
}
/**
* ChatGPT APIリクエスト
* @param {string} text チャットテキスト
* @param {number} max_tokens 出力テキストの最大トークン数。1トークンは約4文字、または英語のテキストでは0.75語
* @param {string} model GPT-3モデル
* @param {boolean} stoped 句点(。)で出力文章を切るかどうか
* @param {*} callback APIのレスポンス処理
* @param {*} errCallback エラー時処理
*/
function requestChatGPT(text, max_tokens=300, model, stoped=false, callback, errCallback){
let stopword = null;
if(stoped) {
stopword = "。";
}
// OpenAI SDKのチャット処理をリクエストする
openai.createCompletion({
model: model,
prompt: text,
temperature: 0.7,
max_tokens: max_tokens,
stop: stopword
}).then((res)=>{
callback(res.data);
}).catch((err) => {
errCallback(err);
});
}
// リッスンするポート
LISTEN_PORT = 3000;
const app = express();
// サーバを起動する
app.post('/', (req, res) => {
postevent(req, res);
});
app.listen(LISTEN_PORT);
console.log('Server running : http://localhost:' + LISTEN_PORT);
コードを保存したら、コマンドプロンプト上でnpm startと入力してください。
> npm start > chatsample@1.0.0 start > node index.js Server running : http://localhost:3000
これで、http://localhost:3000/で待ち受けできる状態になりました。
会話をしてみる
詳細は後で詳しく解説しますが、このコードではHTTP POSTコマンドで以下のJSONを投げると、それに応じた会話を返すという仕組みになっています。
{
"text":"(チャットの質問内容。「気分はどう?」等)"
}
それではさっそく試してみましょう。先ほどプログラムの実行を行ったものとは別のコマンドプロンプトを開いて、以下のように入力してください。
> curl -X POST http://localhost:3000 -d "{\"text\":\"こんにちは\"}"
実行すると、APIが呼び出されて返答が画面に表示されます。
c:\>curl -X POST http://localhost:3000 -d "{\"text\":\"こんにちは\"}"
{"text":"、皆さん\n\nお元気ですか?私は元気です。今日は晴れた素晴らしい1日ですね。"}
続けて会話を入力していってみます。同じ質問でも回答が変わるなど、ChatAPIの機能を利用した会話を行うことができます。
c:\>curl -X POST http://localhost:3000 -d "{\"text\":\"こんにちは\"}"
{"text":"、皆さん\n\nお元気ですか?私は元気です。今日は晴れた素晴らしい1日ですね。"}
c:\>curl -X POST http://localhost:3000 -d "{\"text\":\"今日は何の日?\"}"
{"text":"\n\n今日は2020年7月8日です。日本では海の日です。"}
c:\>curl -X POST http://localhost:3000 -d "{\"text\":\"さようなら\"}"
{"text":"\n\nGoodbye!"}
コードの解説
コードの各所の大まかな解説をしていきます。まず、以下の箇所でOpenAI SDKの初期化をおこなっています。
const configuration = new Configuration({
apiKey: API_KEY,
organization: ORG_KEY,
});
const openai = new OpenAIApi(configuration);
「function postevent」メソッドは、クライアントからのリクエストを処理する関数です。「let body」にリクエスト内容を記録し、リクエスト受信が完了したら内容を確認して実際のチャット処理を呼び出します。
「function requestChatGPT」メソッドは、OpenAI SDKを使ってチャットを実行する関数です。詳細は後述します。
コード末尾の下記部分ではPC上にローカルサーバを立ち上げています。
LISTEN_PORT = 3000;
const app = express();
// サーバを起動する
app.post('/', (req, res) => {
postevent(req, res);
});
app.listen(LISTEN_PORT);
requestChatGPTメソッドでは、OpenAI SDKのcreateCompletionメソッドを呼び出しており、これが実際の呼び出し処理に相当します。OpenAI SDKの処理内容の説明の前に、SDKに関係する「モデル」と「トークン」の概念について簡単に説明します。
モデルとは「言語モデル」のことで、平たく言うと生成AIの性格や賢さを定義したようなものになります(若干説明に齟齬があったらすみません)。利用できるモデルは、ソース内に定義しているdavinci,curie,babbage,adaなどがあります。サンプルソースではdavinciに固定していますが、こちらを別のものに差し替えて試してみてください。
トークンとは、会話の内容を、言語モデルが理解できるように分割したものの単位です。単語や文節・句読点等の要素で分かれることが多いようです。また、日本語・英語といった言語の種類によってもトークンのカウントは変わります。
モデル・トークンはSDKの利用コストに直結しており、基本的に「{入力トークン(質問文)+出力トークン(返答)}×モデルの利用単価」の構図になります。長い文章でトークン数が多くなったり、高品位(高性能)なモデルを使うほど値段が高くなります。
これらの概念を理解したところで、SDKのcreateCompletionメソッドについて説明します。サンプルソースでは以下の引数を設定しています。このうち、modelは使用する言語モデル、propmtは質問文、temperatureは返答内容のランダム性(0.0-1.0の範囲)、max_tokensは生成する返答内容の最大トークン数の指定、stopは文末を示す句読点の明示となります。
openai.createCompletion({
model: model,
prompt: text,
temperature: 0.7,
max_tokens: max_tokens,
stop: stopword
})
メソッドを実行して得られたレスポンスから返答を取得する際は、choicesという配列の各要素からtextの変数を取得します。サンプルソースでは、以下の部分で返答のテキストを取得してクライアントに返しています。
resData.text = data.choices[0].text;
let jsonData = JSON.stringify(resData);
response.writeHead(200);
response.end(jsonData);
createCompletionメソッドには、他にも返答内容(精度他)を細かく指定する引数が存在します。英語にはなりますが、下記の公式ドキュメント・リファレンスも参考になるかと思います。
https://platform.openai.com/docs/introduction
https://platform.openai.com/docs/api-reference
次回予告
今回のアプリを応用し、Sota本体を同一LANに接続して、「http://(アプリを動かしているPCのICアドレス):3000」に対してリクエストする処理を実装すれば、SotaからAPIを呼び出すことができます(Sota本体内にnodejsをインストールして実行させるでも可)。
また、その前後に音声認識・合成を入れることで、Sotaを使って音声ベースでOpenAI SDKを用いた対話を行うことができます。次回はそのあたりの実装方法及びもうちょっと手の込んだ会話にの実装等について説明したいと思います。