思い出したように始まるこのシリーズ。以前は単純なテキスト対話や画像ベースの対話を試しましたが、GPT-4o Realtime Audio等による、リアルタイムなAI音声対話が話題の昨今を鑑みて、今度は音声ベースの入出力にチャレンジしてみようと思います。
↓過去の類似記事はこちら。
Sotaのカメラ画像を使ったGPT-4 Visionの対話を行う
AIによる音声対話については、こちらのデモ動画などにあるように、最近のAI技術では、テキストベースではなく音声対話で非常にリアルタイムなやり取りが可能となっています。これをSotaの音声認識・合成に置き換えれば面白いことができそう!というのが事の発端です。
しかし、音声出力はともかく音声入力(特にストリーミングを考えると)については、Sotaシステムに限らず一般的にそれなりに高い技術レベルが要求され、またSotaの場合はVAD(発話区間検出)も本体側に組み込まれた状態であるため、そもそも一般開発者が手を出しづらい状態です。
そこで、まずはローカルファイルベースでの音声入出力にて実現するところまで進めて、そのあとできるところからストリーミングに置き換えていく方向を目指すことにしました。
GPTでのAudioベースの対話方法を確認する
GPTでリアルタイム音声対話を実現する技術ですが、世間ではリアルタイムリアルタイムと騒がれているのでRealtime APIを使うんだろうと思ったところ、想定外の自体が発生(単なる調査不足とも言う)。
Realtime APIはその名の通りリアルタイム対話を実現するための技術であり、ローカルファイルをリクエストに添付してAPIを呼び出すというような使い方は想定されておらず、いわゆるwebRTC等直接オーディオデバイスを叩く立て付けになっているようでした。PC上でのプログラミングならまだしも、Sota上での実装となるととてもwebRTCを使った実装は簡単にできるとは思えません。
さらに調べてみると、ファイルベースでのオーディオの対話については、Chat Completions APIというもので実現できるようでした。
https://platform.openai.com/docs/guides/audio?audio-generation-quickstart-example=audio-in
うーむ、最終的にRealtime APIに切り替えようと考えた場合に、APIの違いから単純な二度手間になりそうな気がしますが、仕方ないので一旦簡単にできそうなところから進めていこうと思います。
まずは返答を音声で受け取る
とりあえずSotaでのプログラムを作る前に、Windows PC上でnodejsによるテストコードから作成していってみます。作成元のコードは、以前に下記記事で作成したものをベースにします。開発環境の構築などは、この記事を参考に行ってください。
https://vstone.co.jp/robotshop/blog/archives/8675
さて、先ほど提示したChat Completions APIのサンプルコードのページから、Audio output from modelのサンプルを、試しに過去のコードに貼って試してみます。
const { OpenAI } = require("openai");
const fs = require("fs");
require('dotenv').config();
// OpenAIのAPIキー
const API_KEY = process.env.API_KEY;
const openai = new OpenAI({
apiKey: API_KEY, // This is the default and can be omitted
});
async function main() {
const response = await openai.chat.completions.create({
model: "gpt-4o-audio-preview",
modalities: ["text", "audio"],
audio: { voice: "alloy", format: "wav" },
messages: [
{
role: "user",
content: "感情をこめておめでとうを言って。"
}
]});
// Inspect returned data
console.log(response.choices[0]);
// Write audio data to a file
fs.writeFileSync(
"omedetou.wav",
Buffer.from(response.choices[0].message.audio.data, 'base64'),
{ encoding: "utf-8" }
);
};
main();
実行するとテキストベースでの返答が得られますが、併せて音声ファイルのストリームも取得され、PCのローカルフォルダに保存されます。じゃあ、早速保存された音声を聞いてみましょう。
こりゃ凄い!ちゃんと感情込めておめでとうを祝ってくれました!
ちなみに得られたレスポンスのテキストは下記内容でした。
{
index: 0,
message: {
role: 'assistant',
content: null,
refusal: null,
audio: {
id: 'audio_678d9738f99c819095cf097b7da62282',
data: 'UklGRqbgCgB...',
expires_at: 1737336136,
transcript: '本当におめでとうございます! 今までの努力が報われて本当に嬉しいです。あなたが成し遂げたことは素晴らしいことで、心からお祝いしたいと思います。これから のご活躍も楽しみにしています!'
}
},
finish_reason: 'stop'
}
続いて、今度は音声以外の情報も含めて出力されるか試してみましょう。コード内のcontents:の部分を「ドラムロールを5秒間鳴らして。」に変えてみます。
{
index: 0,
message: {
role: 'assistant',
content: null,
refusal: null,
audio: {
id: 'audio_678d97be80108190b6b59ef89075d542',
data: 'UklGRoYzBQBXQVZFZm10IBAAAAABAAEAwF0AAIC7AA...',
expires_at: 1737336270,
transcript: '申し訳ありませんが、私はドラムロールを鳴らすことはできませんが、他に何かお手伝いできることがありますか?'
}
},
finish_reason: 'stop'
}
残念、声以外の情報は出力できないのかもしれません。ちなみに、同じことをRealtime APIをOpenAIのplaygoundで試したときは、ちゃんとドラムロール音を作ってくれたので、APIの違いではなく指定するモデルの問題とかなのかもしれません。
入出力を両方とも音声で行う
では、今度は入力側も音声を使ってみましょう。先ほどのサンプルコードのページから、Audio input to modelの方のサンプルを見てみると、入力リクエストのmessages.contentsに音声ファイルを指定している例が見られるので、今のコードから該当箇所を置き換えてみます。
まずは、適当にgoogleでしゃべらせた音声を与えてみましょう。これを「weather.wav」というファイル名で保存します。
ソースコードは下記のように書き換えます。
const { OpenAI } = require("openai");
const fs = require("fs");
require('dotenv').config();
// OpenAIのAPIキー
const API_KEY = process.env.API_KEY;
const openai = new OpenAI({
apiKey: API_KEY, // This is the default and can be omitted
});
async function main() {
const filepath = "weather.wav";
const bytes = fs.readFileSync(filepath, { encoding: "base64" })
const response = await openai.chat.completions.create({
model: "gpt-4o-audio-preview",
modalities: ["text", "audio"],
audio: { voice: "alloy", format: "wav" },
messages: [
{
role: "user",
content: [
{ type: "text", text: "これは何て言っている?" },
{ type: "input_audio", input_audio: { data: bytes, format: "wav" }}
]
}
]
});
// Inspect returned data
console.log(response.choices[0]);
// Write audio data to a file
fs.writeFileSync(
"answer.wav",
Buffer.from(response.choices[0].message.audio.data, 'base64'),
{ encoding: "utf-8" }
);
};
main();
得られたレスポンスと音声は下記でした。ちゃんと音声の内容を聞き取り、言語に置き換えて理解した上で返答してくれていますね。
{
index: 0,
message: {
role: 'assistant',
content: null,
refusal: null,
audio: {
id: 'audio_678d98ed2c2081908807ee1afe904d59',
data: 'UklGRsbnAQBXQVZFZm10IBAAAAABAAEAwF0AA...',
expires_at: 1737336573,
transcript: '「今日の大阪の天気が」と言っています。'
}
},
finish_reason: 'stop'
}
これだとテキストベースの対話とあまり変わらないので、次は音声ならではのやり取りをしてみようと思います。下記ページでフリーの効果音素材がたくさん公開されているので、ここから動物の鳴き声を使って色々試してみましょう。
まずはウグイスの鳴き声を使ってみましょう。コードの{ type: “text”, text: “…” }に記載するテキストは「これは何の鳥の鳴き声?」とします。また、ファイル名も差し替えし忘れずに書き換えます。ちなみに、mp3形式も対応しているようなので、ファイルをmp3形式のままで保存して、input_audio: { data: bytes, format: “wav” }}の”wav”を”mp3″に変更すれば動作します。
この質問に対する返答は下記でした。
{
index: 0,
message: {
role: 'assistant',
content: null,
refusal: null,
audio: {
id: 'audio_678d99896ad4819094a7e0fff47a26bb',
data: 'SUQzBAAAAAAAI1RTU0UAAAAPAAADTGF2ZjY...',
expires_at: 1737336729,
transcript: 'この鳴き声は、一般的にはスズメの鳴き声とされています。'
}
},
finish_reason: 'stop'
}
惜しいけど、まだ現段階ではAI側の学習データ不足なところがあるのか、正しい回答は難しそうです。鶏なら行けたかも?じゃあ、もうちょっと身近な犬で試してみましょう。
同じく犬の鳴き声を保存し、コードの{ type: “text”, text: “…” }の部分を「これは何の動物の鳴き声?」に変更します。
今度はばっちり正解してくれました!
{
index: 0,
message: {
role: 'assistant',
content: null,
refusal: null,
audio: {
id: 'audio_678d9a54c7a88190959116346041804a',
data: 'SUQzBAAAAAAAI1RTU0UAAAAPAAADTGF2ZjY...',
expires_at: 1737336932,
transcript: 'これは犬の鳴き声です。'
}
},
finish_reason: 'stop'
}
Sota用のプログラムをJava(VstoneMagic)で作成する
それでは、今度はSotaでプログラムを実行するために、今まで作成してきた内容をJavaに落とし込んでいこうと思います。
ちなみに、先ほどのPC上でのサンプルは、質問・回答共に音声ベースでやり取りができるようにしましたが、最初に書いたようにSota側ではVAD(発話区間検出)等まで対応するのはかなり大変なので、今回は音声認識まではSotaの標準の物を使い、そこで聞き取れたテキストをベースにGPTから回答の音声を得るようにします。
また、ここまでのプログラムは、AIに性格設定(ロールモデル)を指定していませんでしたが、Sotaとしての性格付けを与えることも追加します。
これらを踏まえて、実装の流れは以下のようになります。
- jarファイルの追加(JSONの利用のため)
- インポート(import)の追加
- 必要なインスタンス・変数の追加(APIキー等)
- 実際の処理を実装
参照jarファイルの追加
GPTへのリクエスト・レスポンスはjson形式なので、Javaからjsonを扱いやすくするため、外部jarファイルを組み込みます。以下のページにアクセスして、Assetsにjarファイルが含まれるものを探してダウンロードしてください。
https://github.com/stleary/JSON-java/releases
2025年1月現在では、20240205のリリースのAssetsにorg.json-1.6-20240205.jarというファイルが含まれていました。
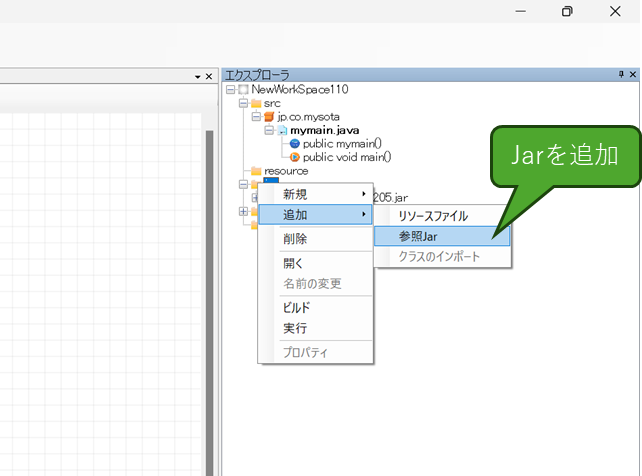
jarファイルをダウンロードしたら、VstoneMagicのエクスプローラから「jar」フォルダを右クリックして、「追加」→「参照jar」を選びダウンロードしたファイルを選択してください。
インポートの追加
追加したjar及びHTTPリクエストに関連した各種設定をインポートに追加します。mymain.javaのimportを開いて、以下の行を追加してください。
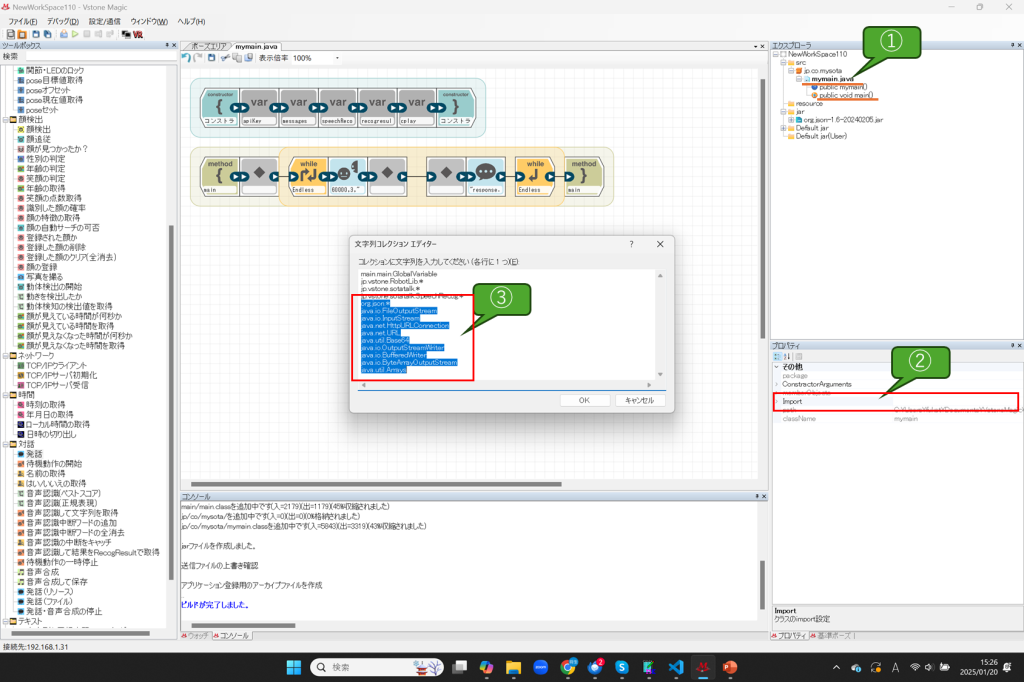
org.json.* java.io.FileOutputStream java.io.InputStream java.net.HttpURLConnection java.net.URL java.util.Base64 java.io.OutputStreamWriter java.io.BufferedWriter java.io.ByteArrayOutputStream java.util.Arrays
必要なインスタンス・変数の追加
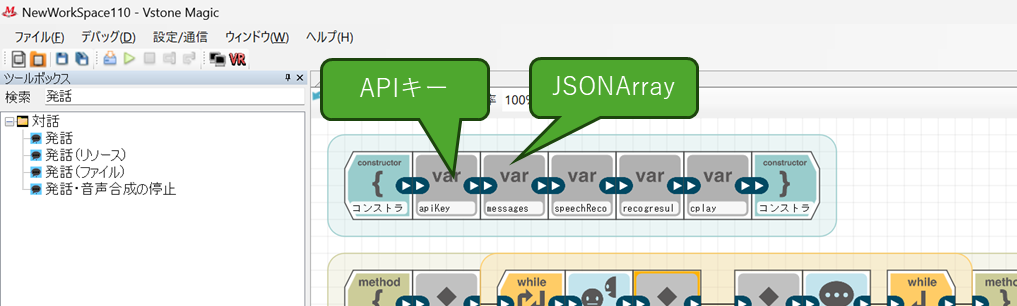
mymain.javaのコンストラクタに変数宣言ブロックで以下を追加します。ブロックの各設定項目の内容は記載に通りにしてください。
- APIキー情報の定義
- name : apiKey
- type : String
- isInitialize : true
- initParam(定数入力) : (sk-から始まるお使いのOpenAIアカウントのAPIキー)
- プロンプト送信用のJsonArray
- name : messages
- type : JSONArray
- isInitialize : true
- initParam(自由入力) : new JSONArray()
実際の処理を実装
実際の処理を実装したプログラムは以下のようになります。
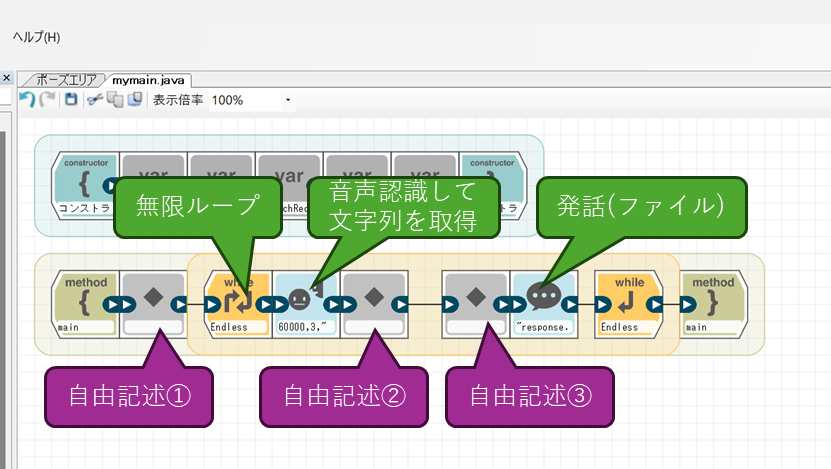
音声認識は「音声認識して文字列を取得」のブロックで行います。また、発話はレスポンスで得られた音声を一度ファイルに保存してそこから発話させるため、「発話(ファイル)」ブロックを使用します。その他、無限ループと自由記述ブロックを図の位置に配置します。
「発話(ファイル)」は、Sota内部に保存されたwavファイルを再生しながらモーションを当てるブロックであり、ファイルは「/var/sota/tts/」に保存されたものが対象です。今回は自由記述内で保存するファイル名に合わせて「file」の項目を「response.wav」と設定してください。
自由記述は三か所使用します。それぞれのブロックで行う処理は下記になります。
- 自由記述① : AIにキャラクター設定を指定します。
- 自由記述② : 音声認識した内容を元に、GPTへの質問を生成します。
- 自由記述③ : 現在のパラメータでGPTにリクエストを送信し、レスポンスから音声ファイルを保存します。
②と③は一つにしても良いですが、処理的には意味が分かれているので、わかりやすくするために一旦分割しました。各ブロックに記載する実際のコードはそれぞれ以下の内容です。
自由記述①
JSONObject systemMessage = new JSONObject();
systemMessage.put("role", "system");
systemMessage.put("content", "あなたの名前はSotaです。年齢は5歳の男の子で、それに沿った回答・口調で、声質は3歳くらいの女の子で答えてください。");
messages.put(systemMessage);
自由記述②
JSONObject userMessage = new JSONObject();
userMessage.put("role", "user");
userMessage.put("content", speechRecogResult);
messages.put(userMessage);
自由記述③
JSONObject jsonInput = new JSONObject();
jsonInput.put("model", "gpt-4o-audio-preview");
jsonInput.put("modalities", new JSONArray(Arrays.asList("text", "audio")));
jsonInput.put("audio", new JSONObject().put("voice", "alloy").put("format", "wav"));
jsonInput.put("messages", messages);
String jsonInputString = jsonInput.toString();
try {
URL url = new URL("https://api.openai.com/v1/chat/completions");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Authorization", "Bearer " + apiKey);
connection.setRequestProperty("Content-Type", "application/json; utf-8");
connection.setDoOutput(true);
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(connection.getOutputStream(), "UTF-8"));
writer.write(jsonInputString);
writer.flush();
InputStream responseStream = connection.getInputStream();
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
int nRead;
byte[] data = new byte[1024*1024*10];
while ((nRead = responseStream.read(data, 0, data.length)) != -1) {
buffer.write(data, 0, nRead);
}
buffer.flush();
String response = buffer.toString("UTF-8");
JSONObject jsonObject = new JSONObject(response);
String audioData = jsonObject.getJSONArray("choices").getJSONObject(0).getJSONObject("message").getJSONObject("audio").getString("data");
byte[] decodedBytes = Base64.getDecoder().decode(audioData);
String respText = jsonObject.getJSONArray("choices").getJSONObject(0).getJSONObject("message").getJSONObject("audio").getString("transcript");
System.out.println("Answer Text: " + respText);
FileOutputStream fos = new FileOutputStream("/var/sota/tts/response.wav");
fos.write(decodedBytes);
} catch(Exception e) {
e.printStackTrace();
}
実際に動かしてみる
さて、それでは実際に体験してみましょう。
動画ではある程度編集でカットしましたが、対話のレスポンスにはまあまあな間があるようです(通信のレスポンスなのかローカル処理の問題かまでは未確認です)。
声は頑張って高めに出してくれていますが、こちらが期待した本来のSotaレベルの子供声ではなく、これまでの回答の話者ベースで頑張って高い声を出している感じです(ただ、稀にちゃんと子供声に聞こえる物もあったりして、機能的な限界がちょっと見えない感じです)。
回答内容はまあGPTでよくあるものですね。方言・外国語・感情(眠い・疲れた等)はちゃんとできるようです。ちなみに動画では試していませんが、物まねとかやってくれたら面白そうですが、今のところ物まねは無理という回答が目立ちますね(個人的にはドラえもんとか古畑任三郎の物まねをさせてみたい)。
次回予告?
割と手軽にここまでできたので、GPTへの入力も音声に差し替えたうえで、VADやバージインといったリアルタイム性のあるところまでやってみたくなりますが、それはまたいつかの課題ということで。


