以前SotaでGPTを使った簡単な対話プログラムを作成しましたが、Sotaにはカメラが付いているので、せっかくだからこれを使って今はやりのGPT-4 Visionによる画像ベースの対話プログラムを作ってみたいと思います。
とりあえず以前の以下のエントリーをベースに、OpenAIのアカウント登録・SDKのAPIキー取得や、PC・Sota側の開発環境を整えている前提で進めていきます。
https://vstone.co.jp/robotshop/blog/archives/7814
https://vstone.co.jp/robotshop/blog/archives/7939
このエントリーベースなので、SotaとPCをLANで連携させて、実際のGPTとの通信処理はPC側で行う流れになります。
PCでGPT-4 Visionを使った簡単なサンプルを作成・実行する
まずは、PC側でGPT4 Visionを使った簡単な動作プログラムを作ってみます。
下記URLなどを参考に、指定のURLの画像の内容を教えてもらうプログラムを作成しました。
https://zenn.dev/tomioka/articles/097d9fec28de15
const { OpenAI } = require("openai");
// OpenAIのAPIキー
const API_KEY = "sk-xxxxxx(お使いのOpenAIアカウントのAPIキーに置き換えてください)";
const openai = new OpenAI({
apiKey: API_KEY, // This is the default and can be omitted
});
async function main() {
const response = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: "この画像は何?" },
{
type: "image_url",
image_url: {
"url": "https://www.vstone.co.jp/img/banner_top01.gif",
},
},
],
},
],
max_tokens: 4000
});
console.log(response.choices[0]);
}
main();
この画像は、ロボットショップのバナーです。

プログラムを実行すると、以下の返答が返ってきました。文字などは間違っていますが、概ね正しく画像を認識してくれています。
> node .\index.js
{
message: {
role: 'assistant',
content: 'この画像は「ROBOT SHOP」と書かれた看板のようです。黄色のロボットのイラストがあり、日本語で「ロボット専門通販 日夜な品揃え!」と記載されています
。これはロボット製品を販売している店舗やオンラインショップの広告である可能性が高いです。'
},
finish_reason: 'stop',
index: 0
}
特定のURLにある画像だけでなく、PC内のファイルなどから画像データを取得し、base64にエンコードして直接投げることもできます。
作成したプログラムを以下のように変更してみました。サンプルとして使用した画像は、以下のSotaの画像を取得しています。
https://www.vstone.co.jp/products/sota/img/sotaimage02.jpg

const { OpenAI } = require("openai");
const fs = require("fs");
// OpenAIのAPIキー
const API_KEY = "sk-xxxxxx(お使いのOpenAIアカウントのAPIキーに置き換えてください)";
const openai = new OpenAI({
apiKey: API_KEY, // This is the default and can be omitted
});
async function main() {
// 読み込むファイル名(※実際に読み込ませるファイルを準備してファイル名を置き換える)
const filepath="sotaimage02.jpg";
// ファイル名から画像形式を取得
const fmt = filepath.split('.').pop().toLowerCase();
const response = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: "この画像は何?" },
{
type: "image_url",
image_url: {
url: `data:image/${fmt};base64,${fs.readFileSync(filepath, { encoding: "base64" })}`,
},
},
],
},
],
max_tokens: 4000
});
console.log(response.choices[0]);
}
main();
実行した結果は以下のようになります。さすがにSotaというキャラクターは知らないようですが、ちゃんと画像に合った回答をしてくれています。
> node .\index.js
{
message: {
role: 'assistant',
content: 'この画像には、白と青の色を基調としたロボットが写っています。人間のような形をした目と表情が特徴的で、子供向けの教育やプログラミングを学ぶための ロボットのように見えます。しかし、このロボットの具体的なモデル名やメーカー名などの詳細についてはコメントすることはできません。'
},
finish_reason: 'stop',
index: 0
}
これで、PC側で様々な画像をGPTに送信してテキストを得る部分はできそうです。
Sotaでカメラ画像を取得してPCに送信する
①カメラ画像を中画質で速く取得する
続いて、Sota側のプログラムも準備します。こちらは、何は無くともまずはカメラから画像を取得する必要があります。
Sotaでカメラ画像を取得する方法は、標準の写真撮影ブロックがまず思いつきますが、こちらは画質が非常に良い一方で取得に時間がかかりすぎるので、対話としては組み込みづらい面があります。
また、写真は高画質過ぎるので、GPTのトークンも消費しがちです。これらを改善するために、
- 1枚の画像取得時間を短縮する
- そこそこの画質に抑える
ということを目標に作成してみます。
写真撮影ブロックの中身についてソースコードを確認すると、以下の内容になっています。
最初の2行は画像の保存先ファイルパスの作成、次の2行はフェイストラッキングを行っている場合はその停止をしています。
String filepath = "/var/sota/photo/";
filepath += (String)"picture";
boolean isTrakcing=GlobalVariable.robocam.isAliveFaceDetectTask();
if(isTrakcing) GlobalVariable.robocam.StopFaceTraking();
GlobalVariable.robocam.initStill(new CameraCapture(CameraCapture.CAP_IMAGE_SIZE_5Mpixel, CameraCapture.CAP_FORMAT_MJPG));
GlobalVariable.robocam.StillPicture(filepath);
CRobotUtil.Log("stillpicture","save picthre file to \"" + filepath +"\"");
if(isTrakcing) GlobalVariable.robocam.StartFaceTraking();
実際に写真を撮影しているのは、5~6行目の2行になります。
自由記述ブロックで下記の2行を実行すると、指定の保存先に画像が保存されることを確認できます。また、処理時間はinitStillに時間がかかっており、一度initStillを実行したら同じ設定で連続的に画像を撮影できるようです。
GlobalVariable.robocam.initStill(new CameraCapture(CameraCapture.CAP_IMAGE_SIZE_5Mpixel, CameraCapture.CAP_FORMAT_MJPG));
GlobalVariable.robocam.StillPicture("※保存先の任意のファイルパスを指定");
ということは、以下のようにプログラムの冒頭で一度だけinitStillを実行すれば、あまり時間をかけずに画像を撮影できそうです。
GlobalVariable.robocam.initStill(new CameraCapture(CameraCapture.CAP_IMAGE_SIZE_5Mpixel, CameraCapture.CAP_FORMAT_MJPG));
while(){
GlobalVariable.robocam.StillPicture("※保存先の任意のファイルパスを指定");
}
また、画質については、initStillの引数CameraCapture.CAP_IMAGE_SIZE_5Mpixelが設定に相当します。画質の設定値については、以下のJavadocに記載されています。
https://sota.vstone.co.jp/sota/javadoc/jp/vstone/camera/CameraCapture.html
とりあえず今回はHD720P(1280×720)で撮影しようと思います。
ということで、ここまでの内容をプログラムに置き換えると以下のようになります。最初に自由記述ブロックでinitStillを実行し、そのあとにループを作成し、その中でStillPictureの処理を実行します。
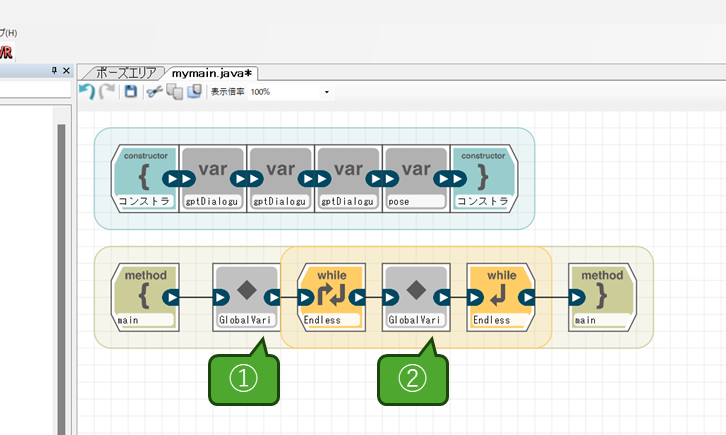
①の自由記述ブロックの内容は以下になります。
GlobalVariable.robocam.initStill(new CameraCapture(CameraCapture.CAP_IMAGE_SIZE_HD_720, CameraCapture.CAP_FORMAT_MJPG));
②の自由記述ブロックの内容は以下になります。StillPictureメソッドの注意点として、ファイルの拡張子は自動的に追加されます。この場合は、/var/sota/photo/file.jpgというファイルとしてSota内に保存されます。
GlobalVariable.robocam.StillPicture("/var/sota/photo/file");
②画像をテキスト(base64)形式に変換する
カメラ画像の連続撮影の次は、撮影した画像をbase64に変換する処理を実装します。
画像データはファイルとして保存されるので、まずは以下を参考に、保存されたファイルを開いてbase64エンコードする処理を実装していきます。
https://qiita.com/riversun/items/76f2305d554228cab4e2
まずは、mymain.javaのimportの設定に以下を追加します。追加する操作は以下の通りです。
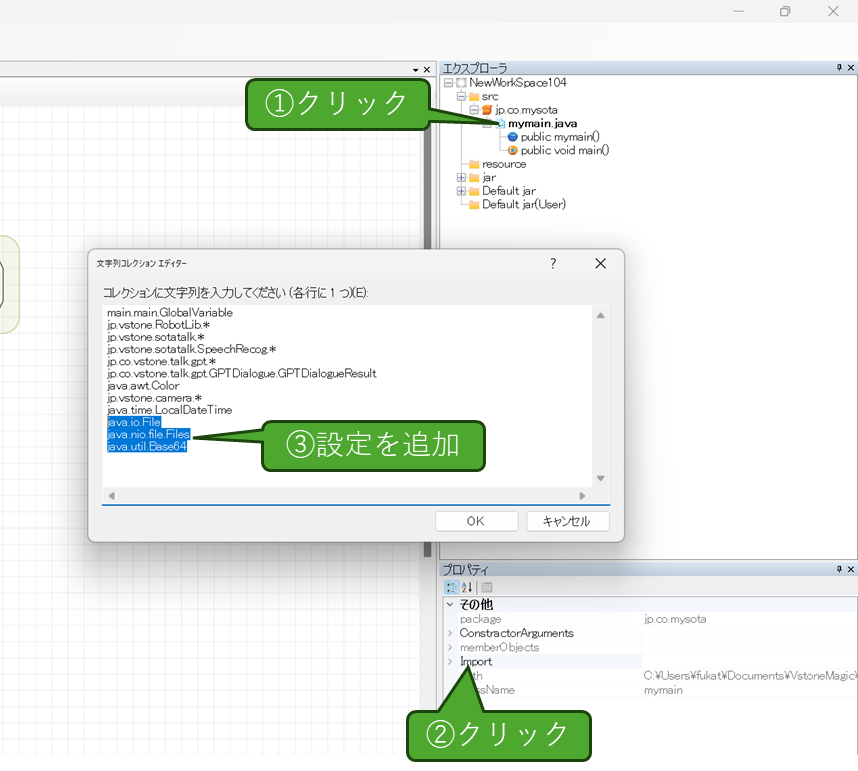
実際に追加する内容は下記になります。
java.io.File java.nio.file.Files java.util.Base64
次に、ループ内の写真撮影の処理の次にもう一つ自由記述ブロックを追加し、保存されたファイルを読み込んでエンコードする処理を作成します。
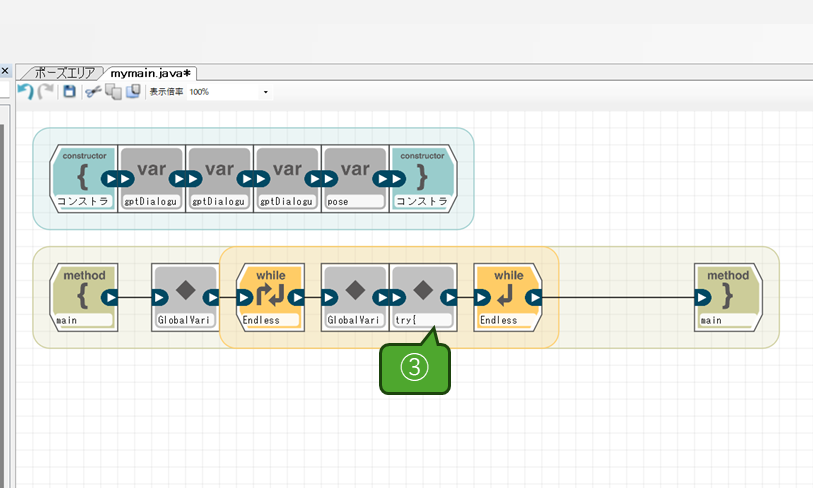
ブロック内に記述するコードは以下の内容です。
try{
// 変換元のファイル
File file = new File("/var/sota/photo/file.jpg");
// ファイルのコンテンツタイプをしらべる
String contentType = Files.probeContentType(file.toPath());
// ファイル内容をbyte[]に読み込む
byte[] data = Files.readAllBytes(file.toPath());
// byte[]をbase64文字列に変換する
String base64str = Base64.getEncoder().encodeToString(data);
// POST用文字列を作成
StringBuilder sb = new StringBuilder();
sb.append("data:image/jpeg");
sb.append(";base64,");
sb.append(base64str);
// 結果を表示
System.out.println(sb.toString());
} catch(Exception e) {
e.printStackTrace();
}
プログラムを実行すると、撮影したファイルを開いてbase64に変換し、それをコンソールウィンドウに表示します。正しく変換できているかについて、data:image/~から始まる行をコピーし、以下などのBase64画像データをデコードするページで確認すると、正しく画像が表示されます。
ちなみに、「data:image/jpeg」を追加している所ですが、本来は画像ファイルに従った形式を取得するべきなのですが、今回はここが画像ファイルなのにテキスト形式(text/plain)になってしまいうまくいかなかったので、jpeg形式に固定しています。
ここまで来たら、あとはこの画像データをPCにjsonでHTTP POSTリクエストすればOKです。先ほどの自由記述ブロックに、HTTP POSTリクエストの処理を追加していきます。
ただし、まだPC側のプログラムで受け取る処理ができていないので、先にそちらの着手が必要です。
PC側の受信プログラムを作成する
PC側でSotaからのリクエストを受信するプログラムを作成します。今回はかなり手抜きで、以下のように「①画像データ(base64)」「②質問テキスト」の二つだけを受け付けるようにします。
{
text:"(質問用テキスト)",
image:"data:image....(base64エンコードした画像)"
}
このリクエストを受け付けるサーバプログラムは下記のようになります。
const express = require('express');
const { OpenAI } = require("openai");
require('dotenv').config();
// OpenAIのAPIキー
const API_KEY = "sk-xxxxxx(お使いのOpenAIアカウントのAPIキーに置き換えてください)";
const openai = new OpenAI({
apiKey: API_KEY, // This is the default and can be omitted
});
// リクエストPOSTイベント
function postevent(request, response) {
// リクエストデータを受信し蓄積していく
let body = '';
request.on('data', function(data) {
// dataイベントでデータを受信したらbodyに追加していく
body += data;
});
request.on('end', function() {
// endイベントがきたらbodyをパースしてオブジェクトにする
console.log(body);
let jsonData = JSON.parse(body);
// リクエストデータが存在しない場合
if(!jsonData || !("text" in jsonData) || !("image" in jsonData)) {
response.writeHead(400);
response.end();
return;
}
openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: jsonData.text },
{
type: "image_url",
image_url: {
url: jsonData.image,
},
},
],
},
],
max_tokens: 4000
}).then(result=>{
console.log(result);
console.log(JSON.stringify(result.choices[0]));
response.writeHead(200, {'Content-Type': 'application/json'});
response.end(JSON.stringify({text:result.choices[0].message.content,image:""}));
});
});
}
// リッスンするポート
LISTEN_PORT = 3000;
const app = express();
// サーバを起動する
app.post('/', (req, res) => {
postevent(req, res);
});
app.listen(LISTEN_PORT);
console.log('Server running : http://localhost:' + LISTEN_PORT);
これで、http://(PCのIPアドレス):3000でリクエストを受け付けるようになります。
SotaからのリクエストPOST処理と対話部分を実装
今度はSota側で、PCへのリクエストのPOSTと実際の対話部分を作っていきます。記事の内容の多くは、前回の以下の内容を踏襲しているのでそちらもご参照ください。
PCのIPアドレス確認
まずはPCのIPアドレスを確認します。コマンドプロンプトを開いて「ipconfig」と入力し、表示された項目から「IPv4アドレス」を調べます。
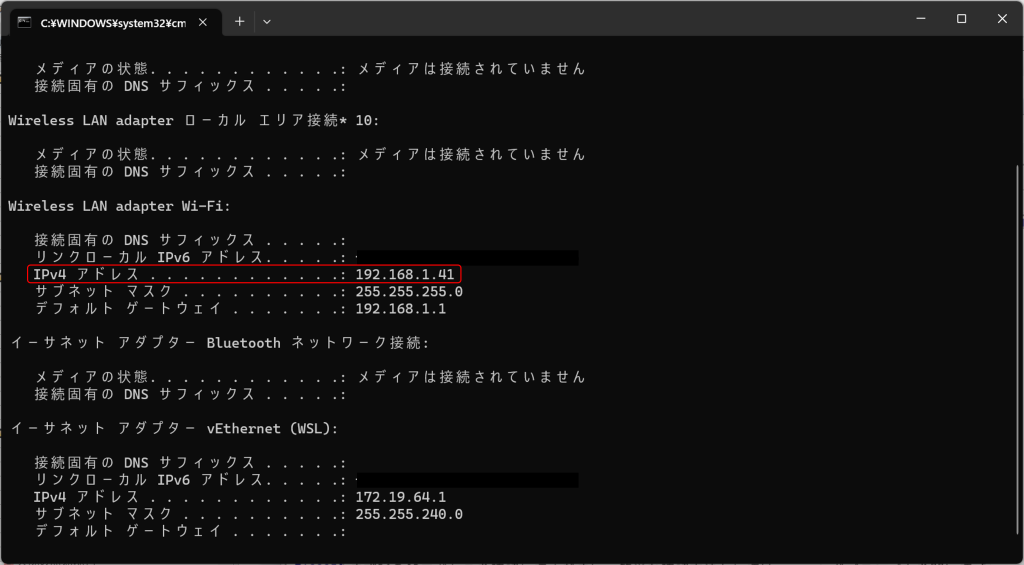
通信に問題がある場合はIPアドレスやネットワーク接続・コマンド記述などに間違いが無いか、ネットワーク設定に問題が無いか(プライバシーセパレータが有効など)等をご確認ください。
リクエスト用クラスの定義
VstoneMagic側では、先ほど作成したプログラムを引き続き使用します。まずは通信用のクラスを作成します。プログラムとの通信はJSON形式の文字列で行うため、それに合わせたクラスを定義しGsonでクラスと文字列の相互変換ができるようにします。
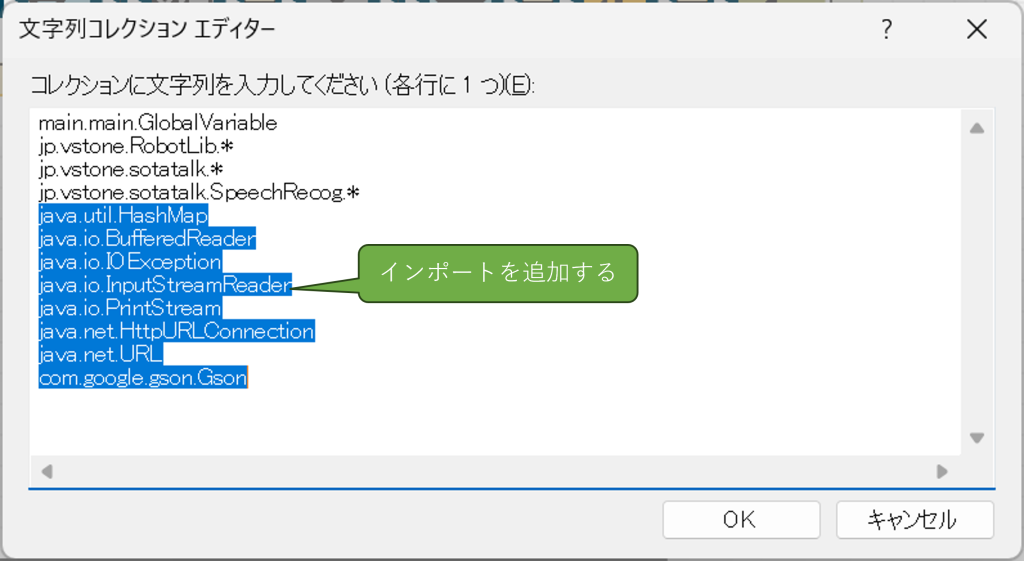
まずは必要なインポートを追加します。mymainクラスをクリックし、「プロパティ」内の「import」を開いて、以下のライブラリを追加してください。
java.util.HashMap java.io.BufferedReader java.io.IOException java.io.InputStreamReader java.io.PrintStream java.net.HttpURLConnection java.net.URL com.google.gson.Gson
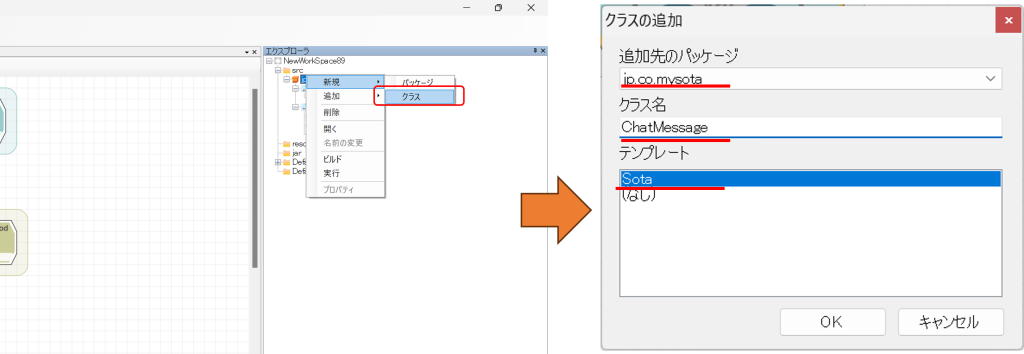
「エクスプローラ」のツリーよりjp.co.mysotaの箇所を右クリックして「新規」→「クラス」をクリックし、ChatMessageというクラスを新規に追加します。
リクエスト・レスポンス用のインスタンスを生成し、HTTP POSTを実行
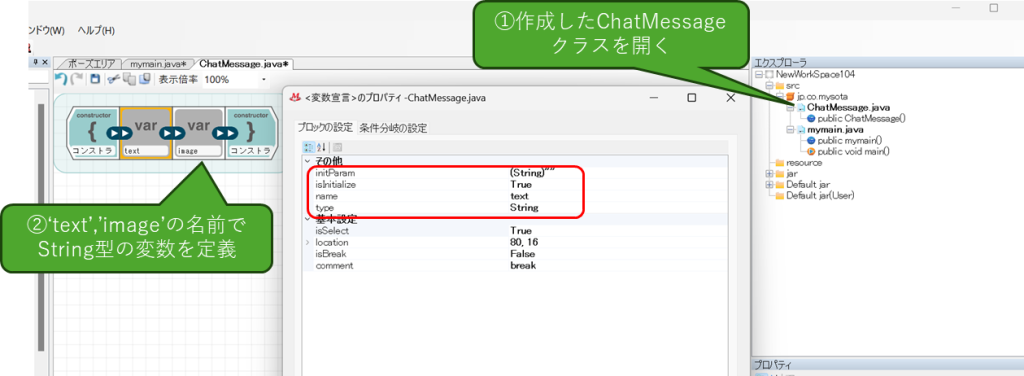
追加したらダブルクリックしてファイルを開き、コンストラクタに「text」「imege」という名前のstring型の変数を、それぞれ追加してください。
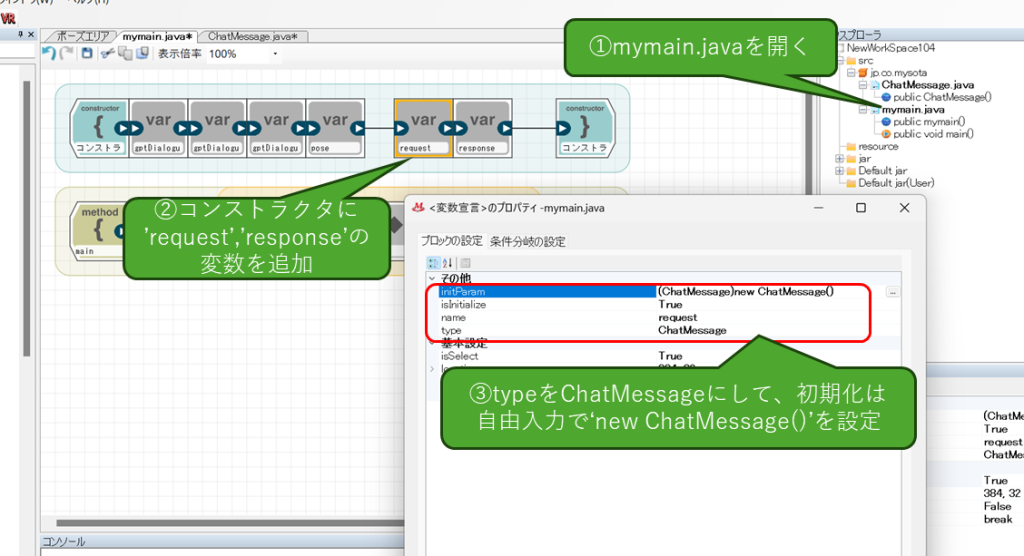
続いてmymainクラスを開いて、コンストラクタに先ほど作成したChatMessageのクラスを二つ追加します。それぞれの名前は、request(入力用)、response(出力用)とします。また、初期化設定を追加してクラスをnewするようにしてください。
今度はrequestに、リクエスト用の内容を作成してPOSTする処理を実装していきますが、その前に、現在のようにループで画像を取得し続ける状態だと、次々GPTのリクエストを送信してしまうので、ループを一度外しておきます。
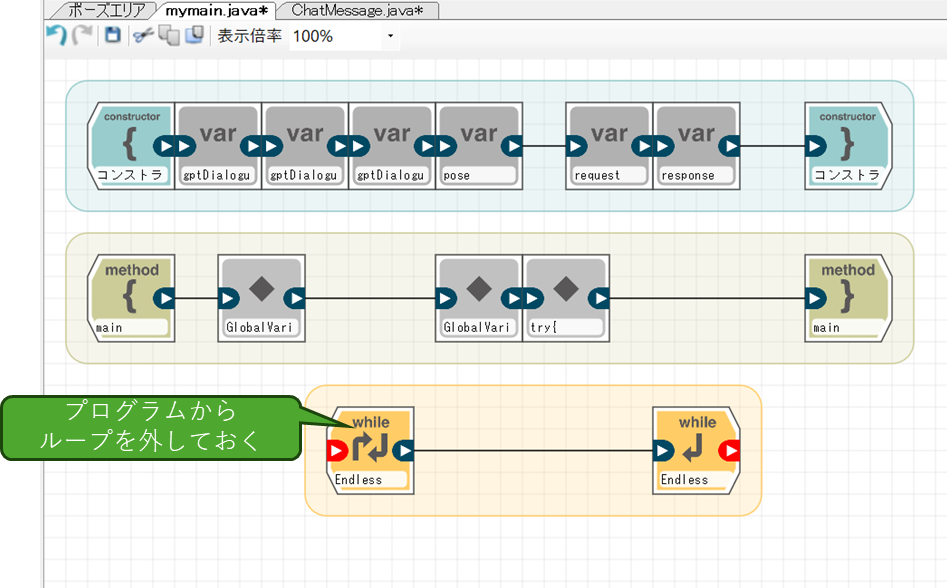
続いて、画像取得・base64変換をしている自由記述ブロックに、requestの内容を生成してPOSTする処理を追加します。ソース内のIPアドレスは、実際のPC側のIPアドレスに置き換えてください。
try{
File file = new File("/var/sota/photo/file.jpg");
String contentType = Files.probeContentType(file.toPath());
byte[] data = Files.readAllBytes(file.toPath());
String base64str = Base64.getEncoder().encodeToString(data);
StringBuilder sb = new StringBuilder();
sb.append("data:image/jpeg");
sb.append(";base64,");
sb.append(base64str);
//--------------ここから追加
// リクエストを作成
request.text="この画像は何?";
request.image=sb.toString();
// PCのサーバにPOST(※IPアドレスは実際の環境に合わせて置き換える)
URL url = new URL("http://192.168.1.40:3000");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "application/json; charset=utf-8");
conn.connect();
Gson gson = new Gson();
String json = gson.toJson(request);
PrintStream ps = new PrintStream(conn.getOutputStream());
ps.print(json);
ps.close();
// リクエスト結果がOK(200)なら、レスポンス内容を取得する
if (conn.getResponseCode() == 200) {
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), "UTF-8"));
sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
sb.append(line);
}
br.close();
// 取得したレスポンスを代入し、コンソールに表示する
response = gson.fromJson(sb.toString(), ChatMessage.class);
System.out.println(response.text);
}
//--------------ここまで
} catch(Exception e) {
e.printStackTrace();
}
このプログラムは、通信に成功したら最後にコンソールウィンドウに生成テキストを表示するようにしているので、これで最低限の結果表示ができます。それでは早速このプログラムを実行してみましょう。
実行すると以下の結果が返ってきました。
> VMが開始されました: 現在のコール・スタックにフレームがありません[Info][CRoboCamera]class jp.vstone.RobotLib.CSotaMotion [Info][CRobotSock]Connected server [Info][CRobotMotion]MasterCtrlPeriod 16667.0 [Info][CRoboCamera]initStill [Info][CRoboCamera]StartTask MODE_STILL_PIC この画像は茶色のぬいぐるみを表示しています。このぬいぐるみはウサギのように見え、青いリボンを付けています。画像の背景には、人が座っているような環境がぼんやりと見えますが、焦点はぬいぐるみに当てられています。 main[1] > アプリケーションが終了しましたexitexit logout ロボットとの通信を切断しました。
Sotaのカメラで撮影された画像はこちらです。ちゃんとこの画像に対する回答を生成できているようですね。

対話ベースのプログラムに作り替え
ここまで来たら、あとはもう簡単ですね。ループを戻して、ループの先頭に音声認識ブロックを追加します。これで、音声認識するごとにPCにリクエストがPOSTされるようになり、(勝手にリクエストを送信し続けません(ただ、これでも気を付けないと無駄にリクエストするので注意)。
また、ループの最後に発話ブロックを追加し、PCから受け取った生成テキストを発話させるようにします。
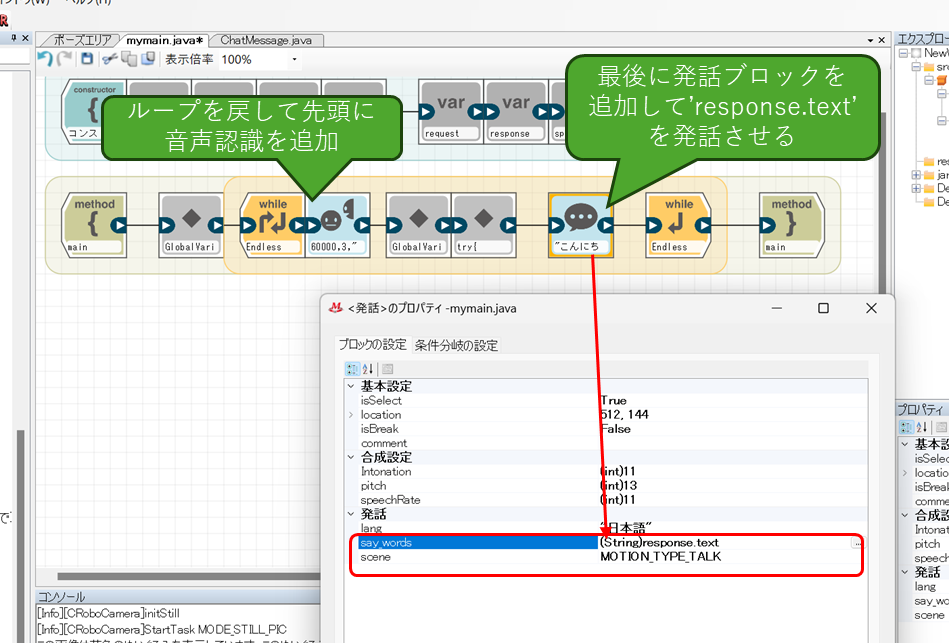
また、現在のプログラムでは、リクエストのテキスト(request.text)が決め打ちのままなので、HTTP POSTを実行している自由記述ブロックを開いて、音声認識した結果を代入するように書き換えます。
try{
File file = new File("/var/sota/photo/file.jpg");
String contentType = Files.probeContentType(file.toPath());
byte[] data = Files.readAllBytes(file.toPath());
String base64str = Base64.getEncoder().encodeToString(data);
StringBuilder sb = new StringBuilder();
sb.append("data:image/jpeg");
sb.append(";base64,");
sb.append(base64str);
// リクエストを作成
//--------------ここを変更
request.text=speechRecogResult;
request.image=sb.toString();
//--------------ここまで
// PCのサーバにPOST(※IPアドレスは実際の環境に合わせて置き換える)
URL url = new URL("http://192.168.1.40:3000");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "application/json; charset=utf-8");
conn.connect();
Gson gson = new Gson();
String json = gson.toJson(request);
PrintStream ps = new PrintStream(conn.getOutputStream());
ps.print(json);
ps.close();
// リクエスト結果がOK(200)なら、レスポンス内容を取得する
if (conn.getResponseCode() == 200) {
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), "UTF-8"));
sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
sb.append(line);
}
br.close();
// 取得したレスポンスを代入し、コンソールに表示する
response = gson.fromJson(sb.toString(), ChatMessage.class);
System.out.println(response.text);
}
} catch(Exception e) {
e.printStackTrace();
}
それでは実験です。ほぼさっきと同じ画像ですが、同じものを見せて質問してみました。

[Info][SpeechRecog]setLangOK [Info][SpeechRecog][getRecognition][Score:0.900138]この動物は何。 [Info][SpeechRecog][getRecognition][BasicResult] この動物は何。 [Info][SpeechRecog]setLangOK この画像には、くまのぬいぐるみが写っています。こちらのぬいぐるみは、キャラクターや実在の動物ではなく、単に玩具のくまとして作られています。
さっきはウサギと認識してくれたのに、どうも気まぐれですね。まあ答えとしては大体合ってますけど。
次の問題。

[Info][SpeechRecog][getRecognition][Score:0.90589565]この人は誰 [Info][SpeechRecog][getRecognition][BasicResult] この人は誰 [Info][SpeechRecog]setLangOK 画像に表示されているのは、実在の人物ではなく、アジアの伝統的なスタイルで描かれた絵の中の人物です。おそらくこれは歴史的な人物か、または伝説上のキャラクターを描いた絵画かもしれませんが、特定の文脈や追加情報がない限り、この人物が誰であるかを正確に特定することはできません。
聖徳太子、知らない!?(この後Sotaがマジ切れすることはありませんでしたのでご安心を)。いや、ネタがやりたかったんじゃなくて、これくらいは知ってるかなって思ったんですけどね。まあ、少なくとも画像をちゃんと認識して答えを生成していることはわかります。
次の問題。
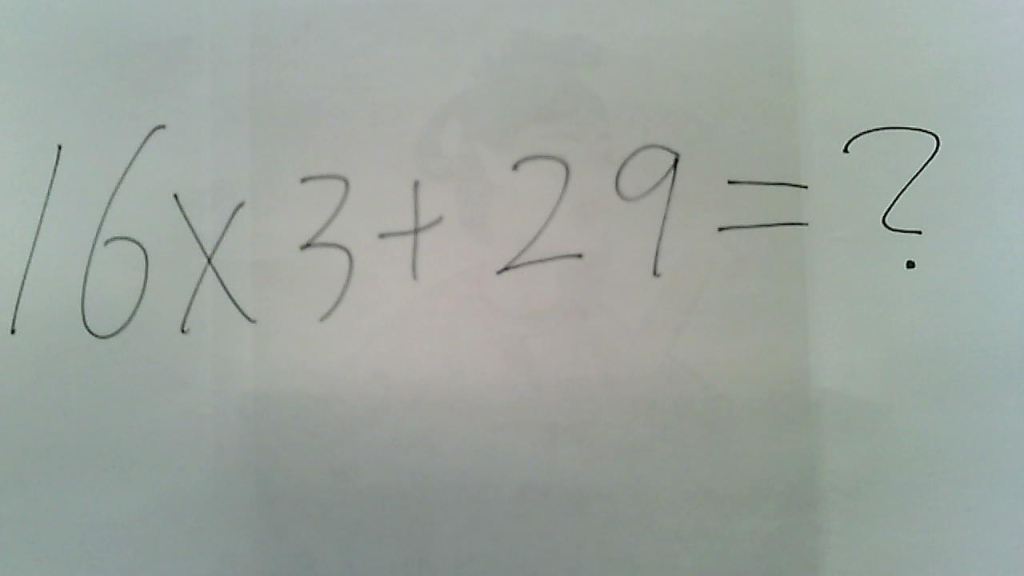
[Info][SpeechRecog][getRecognition][Score:0.9754562]この問題の答えは [Info][SpeechRecog][getRecognition][BasicResult] この問題の答えは [Info][SpeechRecog]setLangOK 申し訳ありませんが、イメージがぼやけていて、数式が明らかではありません。正確な計算を提供するためには、数式のクリアな写真が必要です。数式をテキストで入力いただければ、計算を手伝うことができます。
手書き文字の認識実験。裏写りの聖徳太子が悲しみを誘うSDGs精神あふれる一枚。しかし線が細すぎたのか、数式をちゃんと認識できなかった模様。
それでは線を太くしてリベンジ。
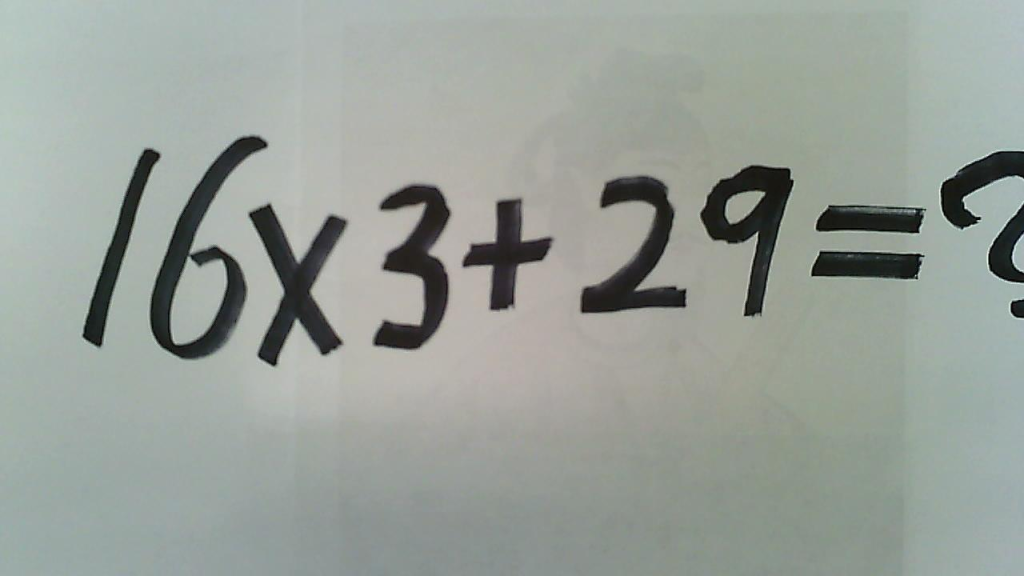
[Info][SpeechRecog][getRecognition][Score:0.991378]この問題の答えは。 [Info][SpeechRecog][getRecognition][BasicResult] この問題の答えは。 [Info][SpeechRecog]setLangOK この写真にある数式を解くと、次のようになります。 16 x 3 + 29 まず、乗算を行います: 16 x 3 = 48 次に、この結果に29を加えます: 48 + 29 = 77 したがって、数式の答えは77です。
ちょっと見切れたのが心配でしたが、やりました!ちゃんと答えてくれました!やったね聖徳太子!
最後に
とりあえずGPT-4 Visionを使ったプログラムができるようになりましたが、実際のレスポンスはまだまだ遅いのが気になります(5秒以上)。ただ、カメラ画像取得だけでなくGPT側のレスポンスの遅さも結構厳しいところがありますね。おそらく将来的には(何年かかるかわかりませんが)GPTのレスポンスは改善されると思いますが、今のところは利用者に遅さを感じさせないような工夫を考える必要がありそうです。
あと、テキストベースではなく画像ベースになると、GPTのトークン消費が肥大しますので、遊ぶときはくれぐれも残りトークン数や利用料金等についてご注意ください。





