「OpenAIのSDKを使ってChat-GPTのような会話をSotade行ってみる」の第2回です。
前回はOpenAIのSDKを使って簡単なプログラムを作成するところまで進めました。今回は実際にSotaを絡めて動かしてみたいと思います。
前回の内容はコチラ↓↓
(前準備)Sota本体から呼び出す
まずは、前回作成したチャットプログラムをSotaから呼び出すところを作ってみたいと思います。
PC側で、前回のプログラムを実行して会話できる状態にしてください。また、SotaをPCと同じLANに接続して下さい。
準備ができたら、念のためSotaからPCの会話プログラムを呼び出せるかチェックします。
まずPCのIPアドレスを確認してください。簡単な確認方法としては、コマンドプロンプトを開いて「ipconfig」と入力し、表示された項目から「IPv4アドレス」を調べる方法などがあります。
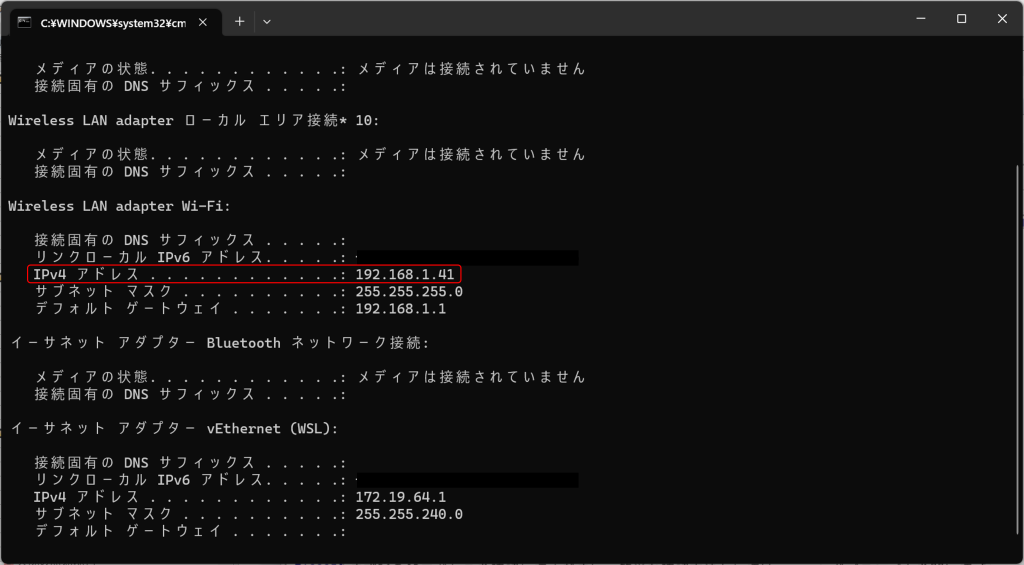
次に、SotaのSSHにアクセスし以下のコマンドを実行します。URLは前回「localhost」だった箇所をPCのIPアドレスに置き換えます。例えばPCのIPアドレスが「192.168.1.41」だったら、「http://192.168.1.41:3000/」のように記述します。
> curl -X POST http://(PCのIPアドレス):3000 -d "{\"text\":\"こんにちは\"}"
コマンドを実行し、前回と同じく返答が帰ってきたらSotaからの会話アプリの呼び出しは成功です。うまく実行できない場合はIPアドレスやネットワーク接続・コマンド記述などに間違いが無いか、ネットワーク設定に問題が無いか(プライバシーセパレータが有効など)等をご確認ください。
VstoneMagicで対話プログラムに組み込む
それでは、実際に会話プログラムを呼び出す処理をVstoneMagicで実装してみます。VstoneMagicで適当なプロジェクトを新規に作成してください。作成したら、まずは通信用のクラスを作成します。プログラムとの通信はJSON形式の文字列で行うため、それに合わせたクラスを定義しGsonでクラスと文字列の相互変換ができるようにします。
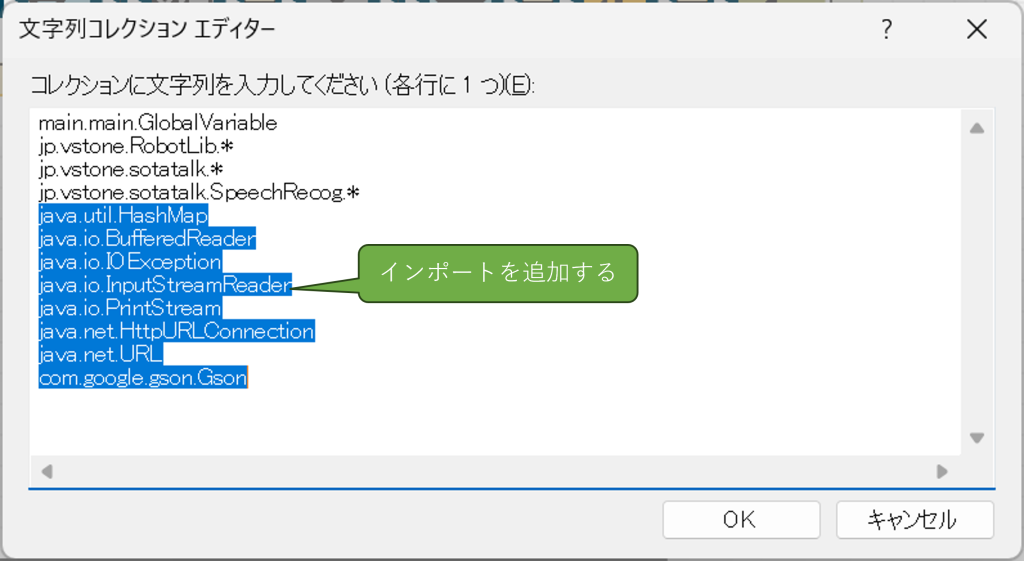
まずは必要なインポートを追加します。mymainクラスをクリックし、「プロパティ」内の「import」を開いて、以下のライブラリを追加してください。
java.util.HashMap java.io.BufferedReader java.io.IOException java.io.InputStreamReader java.io.PrintStream java.net.HttpURLConnection java.net.URL com.google.gson.Gson
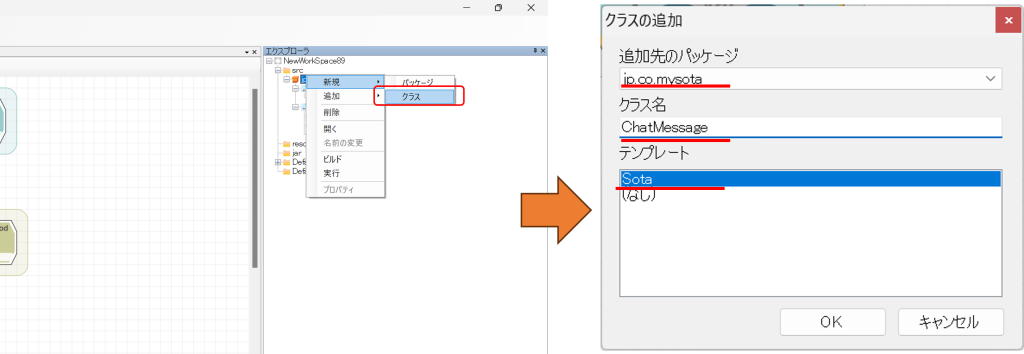
「エクスプローラ」のツリーよりjp.co.mysotaの箇所を右クリックして「新規」→「クラス」をクリックし、ChatMessageというクラスを新規に追加します。
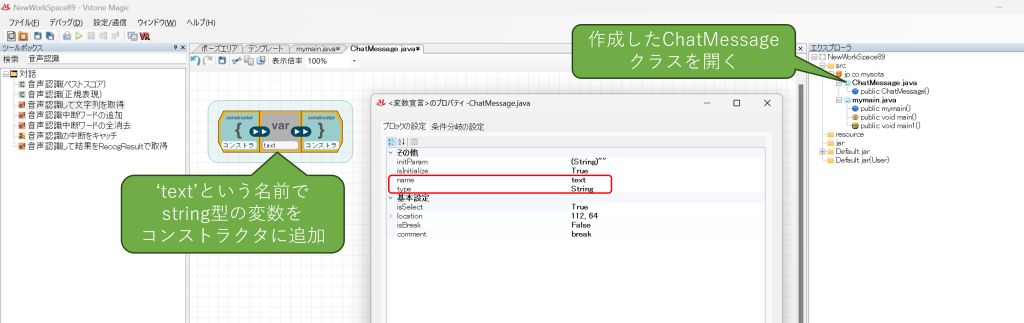
追加したらダブルクリックしてファイルを開き、コンストラクタにtextという名前のstring型の変数を追加してください。会話プログラムのJSONは入出力共に{"text":"(質問及び回答)"}の形式なので、これで双方のデータ変換用クラスが準備できました。
続いてmymainクラスを開いて、コンストラクタに先ほど作成したChatMessageのクラスを二つ追加します。それぞれの名前は、request(入力用)、response(出力用)とします。また、初期化設定を追加してクラスをnewするようにしてください。
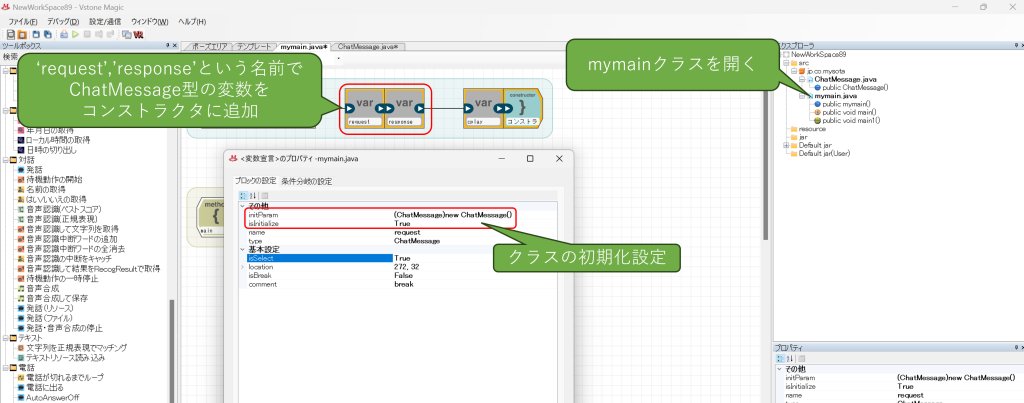
次に、実行メソッドに変数演算ブロックを追加し、ここでrequest.textに質問用のテキストを代入してください。
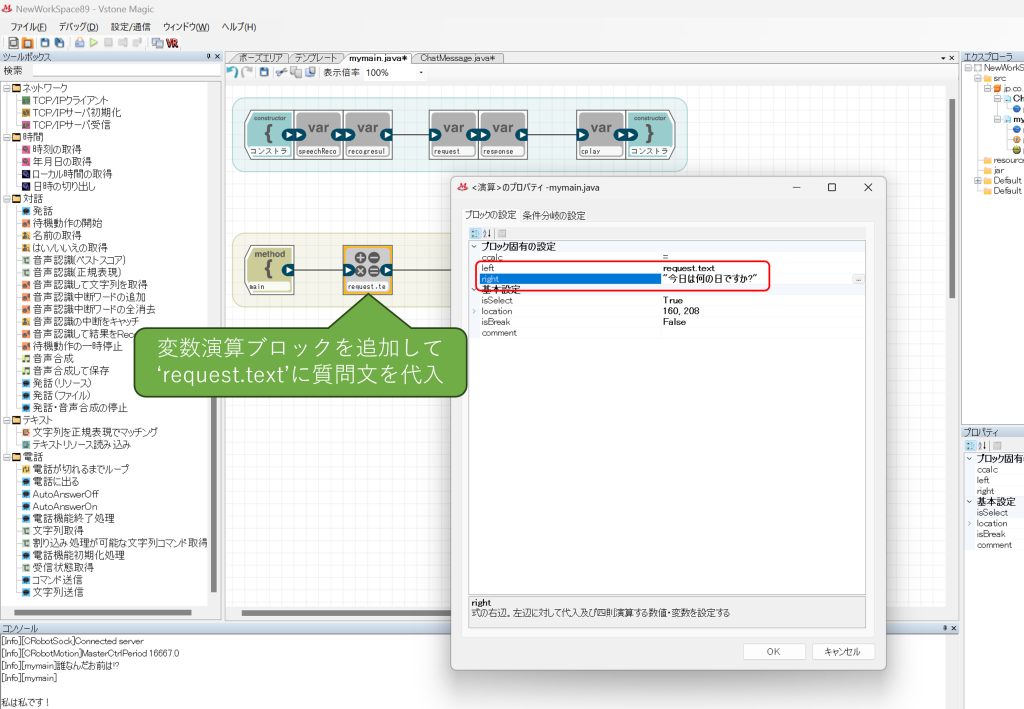
続いてログブロックを二つ追加し、それぞれrequest.text、response.textの内容を出力させるように設定します。こちらは実行結果の確認用です。
続いて二つのログブロックの間に自由記述ブロックを追加し、以下のコードを入力してください。
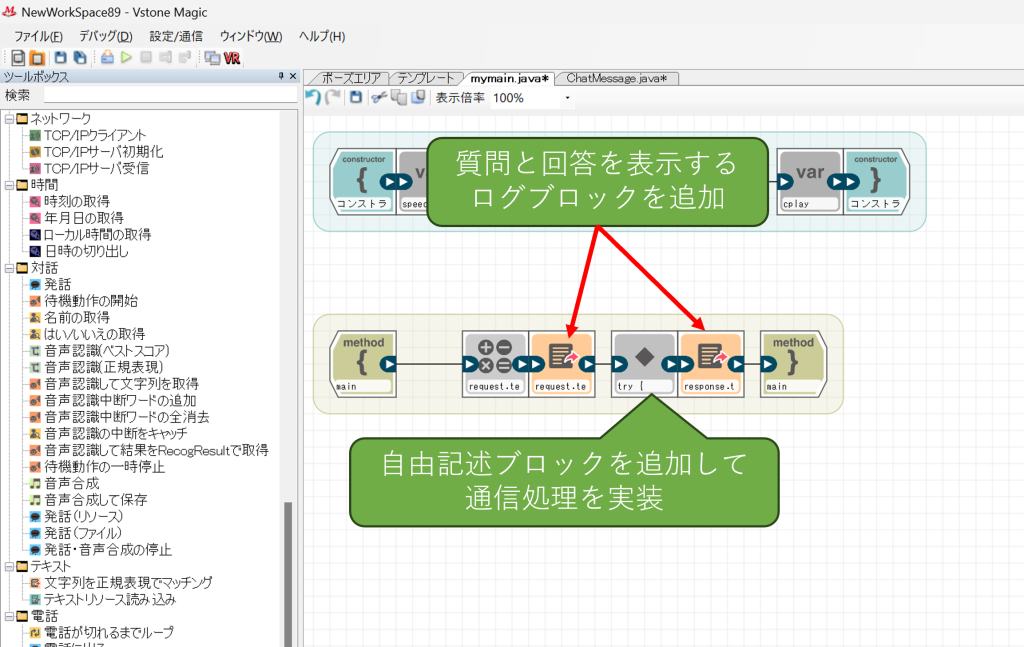
なお、3行目のURL url = new URL("http://192.168.1.41:3000");の箇所は、先ほど確認した会話プログラムを実行しているPCのIPアドレスに置き換えてください。
try {
URL url = new URL("http://192.168.1.41:3000");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "application/json; charset=utf-8");
conn.connect();
Gson gson = new Gson();
String json = gson.toJson(request);
PrintStream ps = new PrintStream(conn.getOutputStream());
ps.print(json);
ps.close();
if (conn.getResponseCode() == 200) {
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), "UTF-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
sb.append(line);
}
br.close();
response = gson.fromJson(sb.toString(), ChatMessage.class);
}
} catch(Exception e) {
e.printStackTrace();
}
実行して、コンソールウィンドウに質問・回答が表示されれば成功です。
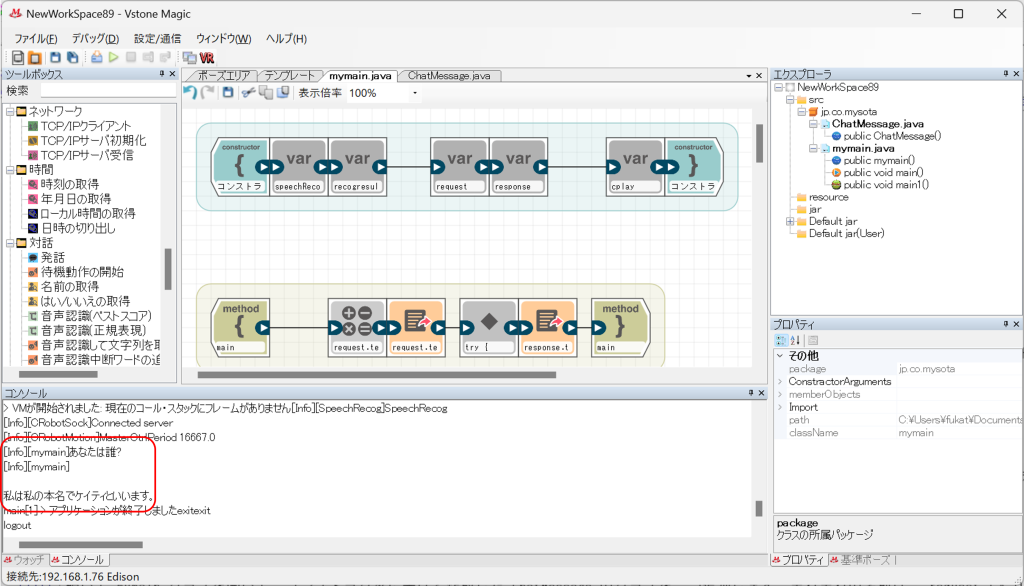
ここまで出来たら、あとはテキストの入出力を音声ベースに置き換えるだけで、音声による対話が可能になります。
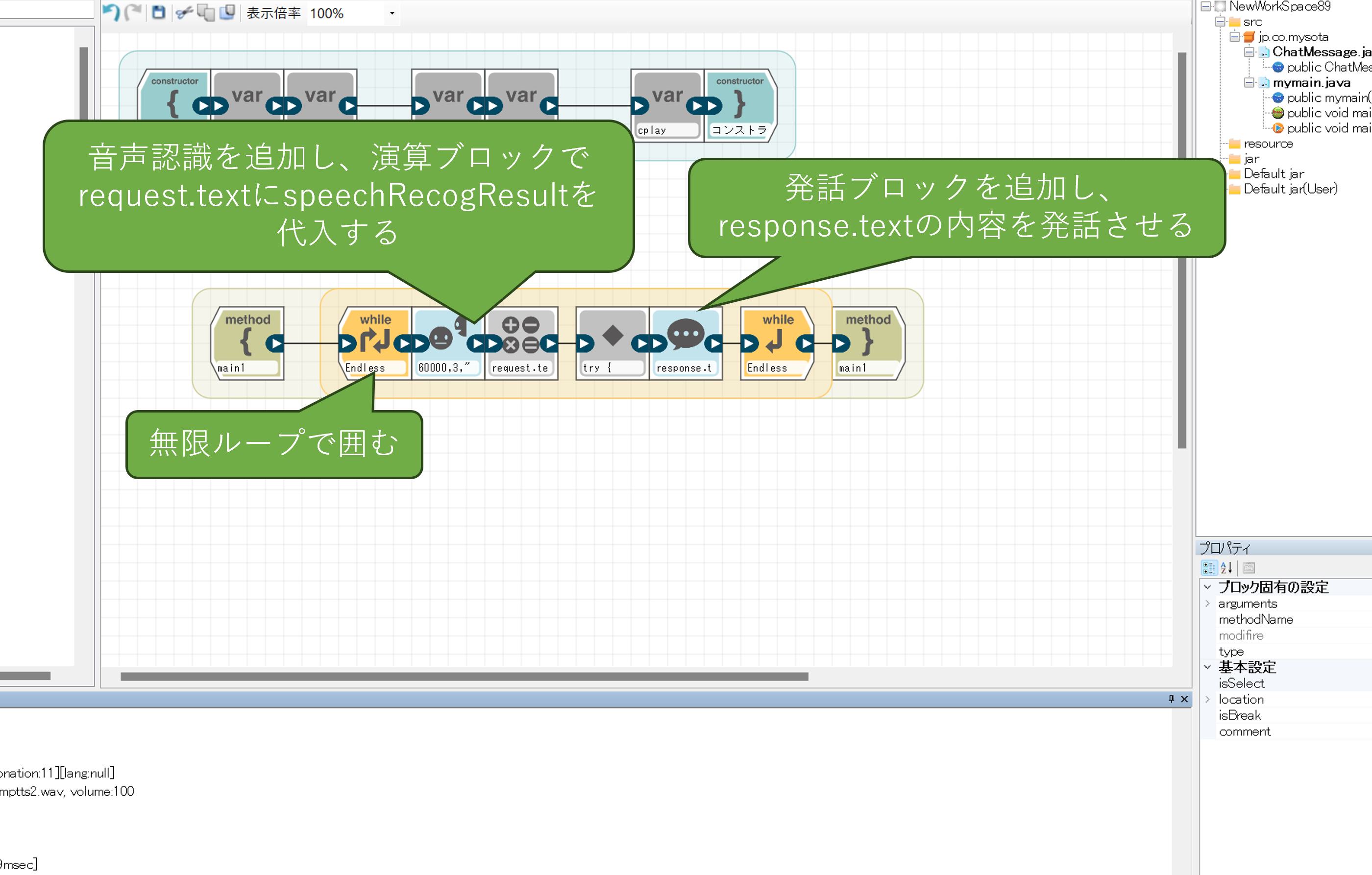
AIのキャラクター設定などを行う
Chat-GPTの技術を使ったAIの中には、「何かのキャラクターになりきって会話する」「料理に特化した会話を行う」等、開発者が任意にカスタマイズしたものが存在します。
このようなちょっと手の込んだ会話を行うにはどうすればよいのでしょうか?
調べてみると、対話の文章自体に加えて、それまでの対話のログやAIに与える役割などの情報を含めてリクエストする必要があるようです。
具体的には、promptではなくmessagesというパラメータに、(user,assistant)や役割(role)といった情報を含めることで、より高品質な会話ができるということがわかりました。
参考ページ
https://zenn.dev/k_kind/articles/chatgpt-api-q-and-a
https://blog.since2020.jp/ai/chatgpt_api_role/
これまでは、APIのリクエストのpromptにユーザの質問文を入れて実行していましたが、これをmessagesに変更し、下記の要素を含めるようにすれば実現できそうです。
{"role":"system","content":"(AIの性格・役割などを指定)"}
{"role":"assistant","content":"(過去の対話ログ)"}
{"role":"user","content":"(ユーザの質問文)"}
一つ考えないといけないのは、AIの性格・過去の対話ログをどこに持たせるかです。シンプルに作ることを考えるとサーバ側に持たせたくなりますが、そうすると例えば複数のSotaで一つのチャットサーバを共有する場合、すべてのSotaの会話が混ざってしまい個別の会話が成り立たなくなってしまうので、クライアント(ロボット)側にAIの性格・対話ログを持たせる必要がありそうです。
それでは、まずはサーバ側を実装してみましょう。上記の通り、サーバ側は逆にシンプルにクライアントから送られてきたmessagesの内容をそのままサーバに伝えれば良いので、その方向で作ります。modelは、これまでの実装ではあらかじめSDKで用意されたモデルを指定していましたが、今回の場合はgpt-3.5-turboを指定する必要があるようです。こちらもそのままコードに実装します。
なお、API_KEY、ORG_KEYはあらかじめ調べた自分のアカウントのものに書き換えてください。
const express = require('express');
const { Configuration, OpenAIApi } = require("openai");
// 最も有能なGPT-3モデル
const MODEL_DAVINCI = "text-davinci-003";
// 非常に有能で、Davinciよりも高速
const MODEL_CURIE = "text-curie-001";
// 簡単なタスク、非常に高速
const MODEL_BABBAGE = "text-babbage-001";
// 非常に単純なタスクが可能で、最速
const MODEL_ADA = "text-ada-001";
const MODEL = MODEL_DAVINCI;
const MAX_TOKENS=300;
// OpenAIのAPIキー
const API_KEY = 'sk-********************************';
// OpenAIのOrganizationキー
const ORG_KEY = 'org-*******************************';
// OpenAIの初期化
const configuration = new Configuration({
apiKey: API_KEY,
organization: ORG_KEY,
});
const openai = new OpenAIApi(configuration);
// リクエストPOSTイベント
function postevent(request, response) {
// リクエストデータを受信し蓄積していく
let body = '';
request.on('data', function(data) {
// dataイベントでデータを受信したらbodyに追加していく
body += data;
});
request.on('end', function() {
// endイベントがきたらbodyをパースしてオブジェクトにする
console.log(body);
let jsonData = JSON.parse(body);
// リクエストデータが存在しない場合
if(!jsonData || !("messages" in jsonData)) {
response.writeHead(400);
response.end();
return;
}
let messages = jsonData.messages;
let maxTokens = null;
let stoped = null;
if("max_tokens" in jsonData) {
maxTokens = Number(jsonData.max_tokens)
}
if("stoped" in jsonData){
stoped = jsonData.stoped
}
requestChatGPT(messages, maxTokens, 'gpt-3.5-turbo', stoped, (data)=>{
console.log(data);
let message = null;
let content = "";
if(data && ("choices" in data) && 0 < data.choices.length
&& ("message" in data.choices[0]) && ("content" in data.choices[0].message)) {
message = data.choices[0].message;
content = data.choices[0].message.content;
}
let resData = new Object();
resData.content = content;
resData.message = message;
let jsonData = JSON.stringify(resData);
response.writeHead(200);
response.end(jsonData);
}, (err)=>{
console.error(err);
response.writeHead(500);
response.end();
});
});
}
/**
* ChatGPT APIリクエスト
* @param {*} messages メッセージデータ配列([{"role": "[ロール]", "content": "[メッセージ内容]"}])
* @param {number} max_tokens 出力テキストの最大トークン数。1トークンは約4文字、または英語のテキストでは0.75語
* @param {string} model GPT-3モデル
* @param {boolean} stoped 句点(。)で出力文章を切るかどうか
* @param {*} callback APIのレスポンス処理
* @param {*} errCallback エラー時処理
*/
function requestChatGPT(messages, max_tokens=300, model, stoped=false, callback, errCallback){
let stopword = null;
if(stoped) {
stopword = "。";
}
openai.createChatCompletion({
model: model,
temperature : 0.7,
max_tokens : max_tokens,
stop : stopword,
messages: messages,
}).then((res)=>{
callback(res.data);
}).catch((err) => {
errCallback(err);
});
}
// リッスンするポート
LISTEN_PORT = 3000;
const app = express();
// サーバを起動する
app.post('/', (req, res) => {
postevent(req, res);
});
app.listen(LISTEN_PORT);
console.log('Server running : http://localhost:' + LISTEN_PORT);
コード入力できたら、再度npm startで実行し、以下の内容をcurlでPOSTしてみます。
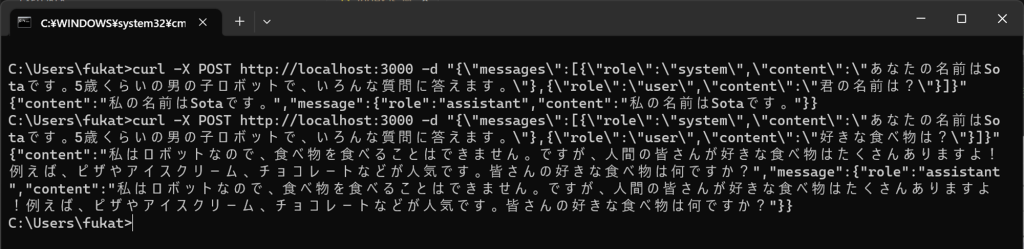
curl -X POST http://localhost:3000 -d "{\"messages\":[{\"role\":\"system\",\"content\":\"あなたの名前はSotaです。5歳くらいの男の子ロボットで、いろんな質問に答えます。\"},{\"role\":\"user\",\"content\":\"君の名前は?\"}]}"
curl -X POST http://localhost:3000 -d "{\"messages\":[{\"role\":\"system\",\"content\":\"あなたの名前はSotaです。5歳くらいの男の子ロボットで、いろんな質問に答えます。\"},{\"role\":\"user\",\"content\":\"好きな食べ物は?\"}]}"
次のような結果が返ってきました。ちゃんと役割を与えられていることがわかります。おそらくassistantを間に挿入すれば、その内容も加味した返答を返してくれそうです。
Sota側のプログラムの改善
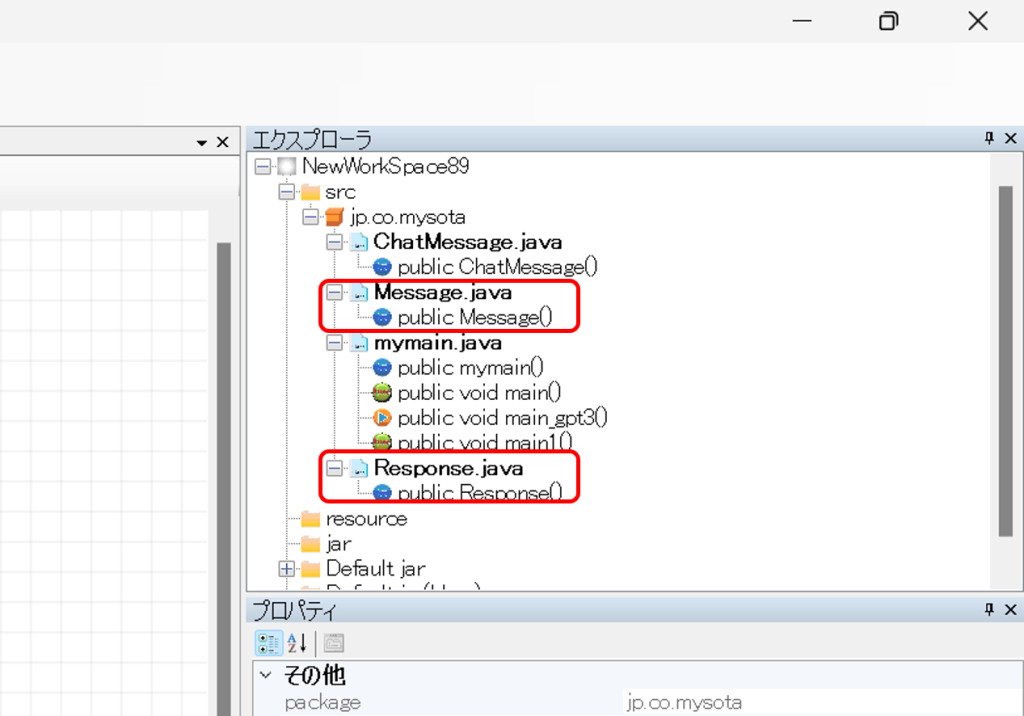
サーバ側のプログラムの変更に従い、Sota側のプログラムも改善していきます。
まずは、必要なクラスを新規作成します。新しいクラスとしてMessage.java、Response.javaを作ります。
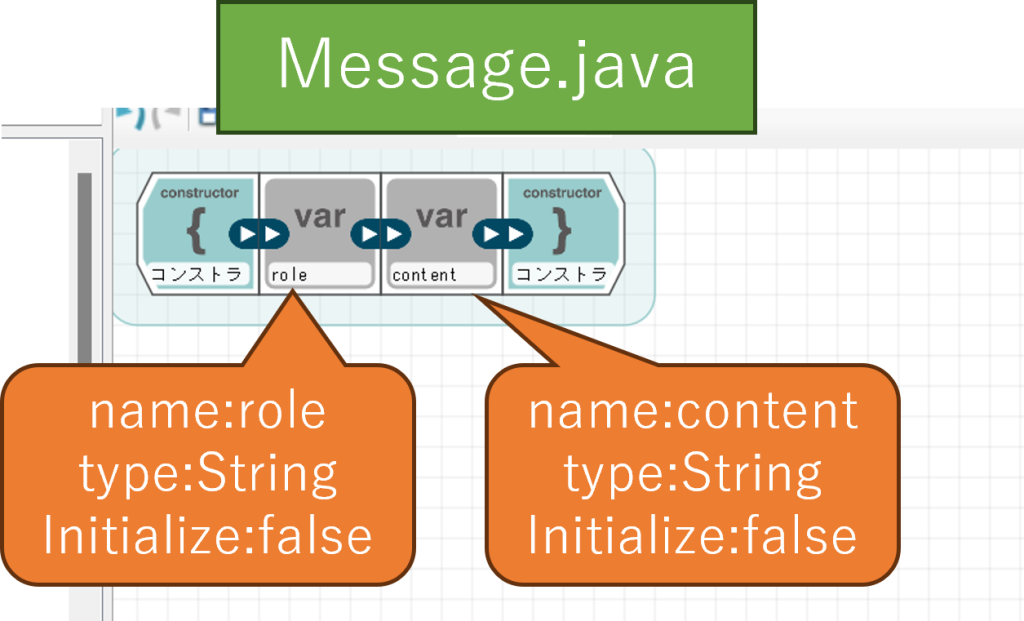
それぞれのコンストラクタに追加する変数は以下の通りです。
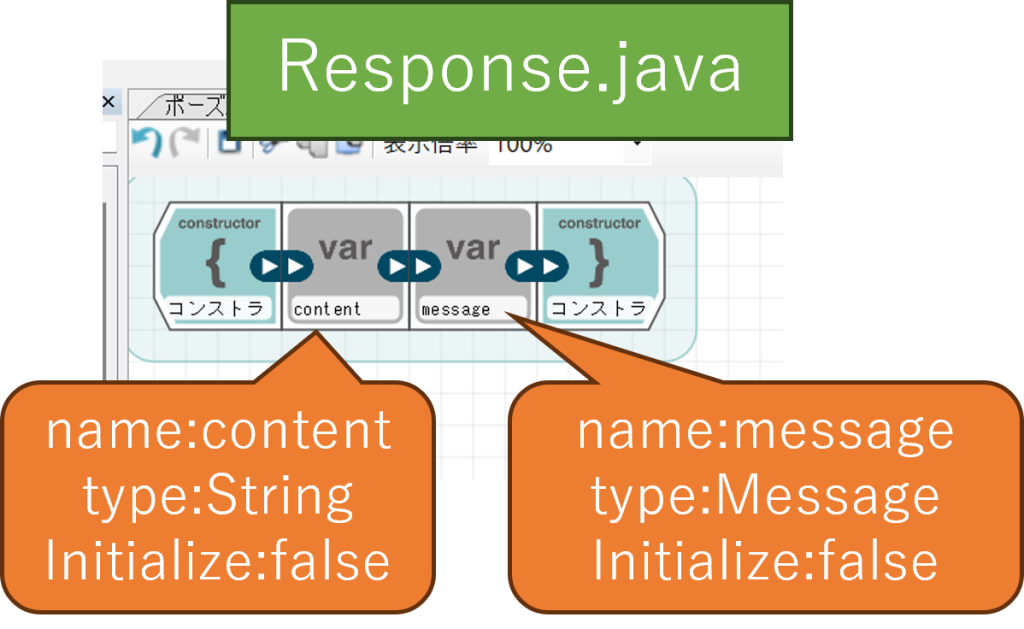
クラスを作成したら、mymain.javaを開いてコンストラクタの設定を変更します。併せて、従来のresponseは名前が重複するので削除(ブロックを外す)し、また発話ブロックの発話テキストもresponse.contentに変更します。
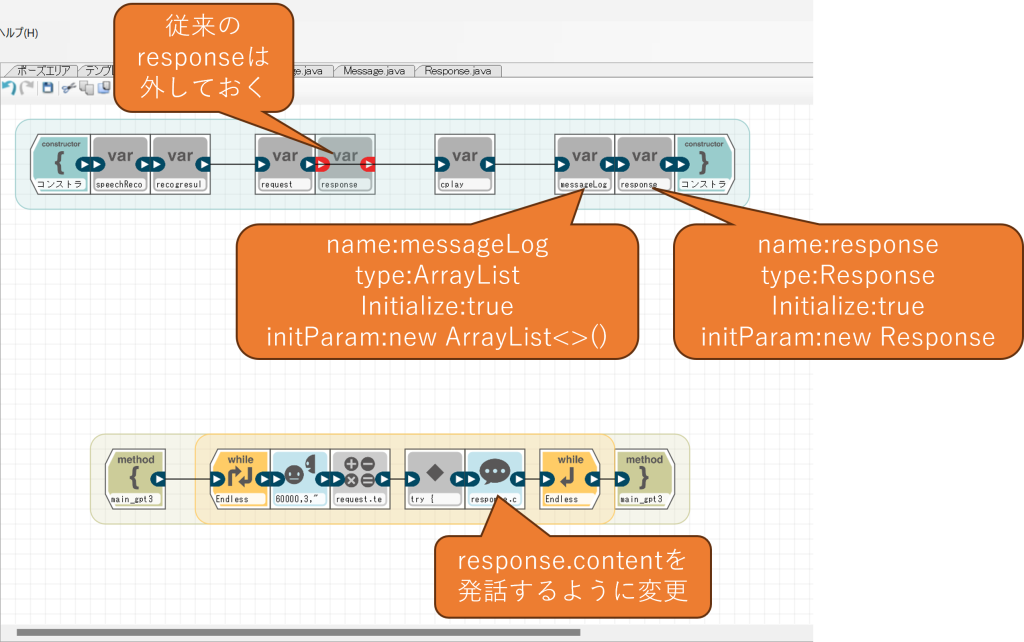
自由記述ブロックのコードは以下のように変更します。冒頭のURLのIPアドレスは、サーバ側のPCのものに差し替えてください。
try {
URL url = new URL("http://192.168.1.42:3000");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "application/json; charset=utf-8");
conn.connect();
// messagesのsystem部分を作成
Message system = new Message();
system.role = "system";
system.content = "あなたの名前はSotaです。5歳くらいの男の子ロボットで、いろんな質問に答えます。";
// messagesのassistant部分を作成
// messagesのuser部分を作成
Message user = new Message();
user.role = "user";
user.content = speechRecogResult;
// messagesを統合
Message[] messages = new Message[messageLog.size()+2];
messages[0] = system;
for(int i=0;i<messageLog.size();i++) messages[i+1] = messageLog.get(i);
messages[messages.length-1] = user;
Gson gson = new Gson();
String json = "{\"messages\":" + gson.toJson(messages) + "}";
PrintStream ps = new PrintStream(conn.getOutputStream());
ps.print(json);
ps.close();
if (conn.getResponseCode() == 200) {
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(), "UTF-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
sb.append(line);
}
br.close();
response = gson.fromJson(sb.toString(), Response.class);
messageLog.add(response.message);
}
} catch(Exception e) {
e.printStackTrace();
}
以上でプログラムは完了です。実際に動かしてみたところ、以下のような対話ができました。途中「二番目は?」と聞いたつもりが「何番目は」と認識されてしまい、ちょっと会話がずれましたが、そのあとの名物の質問などはちゃんとこれまでの受け答えを踏まえて回答できていることがわかります。
Listening for transport dt_socket at address: 8765 捕捉されないjava.lang.Throwableの設定遅延した捕捉されないjava.lang.Throwableの設定jdbの初期化中...デバッグ実行のスタンバイができました。 > VMが開始されました: 現在のコール・スタックにフレームがありません[Info][SpeechRecog]SpeechRecog ... [Info][SpeechRecog][getRecognition][BasicResult] 君の名前は ... [Info][TextToSpeechSota]sotasettings voicetype loaded [Info][MotionAsSotaWish][Say][scene:talk]私の名前はSotaです。どんな質問でもお答えします! [Info][TextToSpeechSota][get:私の名前はSotaです。どんな質問でもお答えします!][speechRate:11][pitch:13]][intonation:11][lang:null] ... [Info][SpeechRecog][getRecognition][BasicResult] よろしく ... [Info][TextToSpeechSota][get:よろしくお願いします!どんな質問がありますか?][speechRate:11][pitch:13]][intonation:11][lang:null] ... [Info][SpeechRecog][getRecognition][BasicResult] 日本で一番長い川は ... [Info][TextToSpeechSota][get:日本で一番長い川は信濃川(しんあのがわ)です。長さは367キロメートルほどあります。][speechRate:11][pitch:13]][intonation:11][lang:null] ... [Info][SpeechRecog][getRecognition][BasicResult] 何番目は ... [Info][TextToSpeechSota][get:信濃川は日本で一番長い川ですが、具体的に何番目かという情報はありません。信濃川は日本を代表する大きな川の一つであり、その美しい景観や歴史的な価値から多くの人々に親しまれています。][speechRate:11][pitch:13]][intonation:11][lang:null] ... [Info][SpeechRecog][getRecognition][BasicResult] そこの名物は ... [Info][TextToSpeechSota][get:信濃川の周辺にはいくつかの名物があります。例えば、信州そばや信州リンゴなどが有名です。また、信濃川流域には美しい景色や温泉地もありますので、観光地としても人気があります。信濃川を訪れる際には、地元の名物や観光スポットを楽しんでみてください!][speechRate:11][pitch:13]][intonation:11][lang:null] [Info][CPlayWave]removeShutdownHook [Info][CPlayWave]Play /dev/shm/wavtemptts4.wav, volume:100 [Info][CPlayWave]isEdison [Info][CPlayWave]play------- 6602 [Info][MotionAsSotaWish]play 23140 [Info][MotionAsSotaWish][play][talk] [22740msec]
これでうまく会話ができそうですね。
ちなみに、一つ注意として、assistantで与える会話ログは長くなるほどトークン数の加算が増えていき、利用料が増えてしまうようです。コスト的な面では、messages全体の要素数は20個程度を上限として、最初の要素に役割(role:system)、最後に質問文(role:user)、その間に最新の会話18件をrole:assistantで登録するのが良いかもしれません。
最後に
これでSotaをChat-GPTで会話させる当初の目的は一応達成しました。ただ、openaiには自然言語処理以外も含めてまだまだ面白そうな機能が備わっているようです。また、対話の質自体も様々なパラメータをチューニングすることで、より高品質な会話ができるようになるかもしれません。今回の記事の内容を基本として、そのような発展的な内容にチャレンジしてみるのも面白いかと思います。





