OpenAIが展開するChatGPTは、テキストベースのAIエンジンであるGPT-4と画像生成エンジンであるDALL-E 3を統合し、ユーザーがテキストを入力することで簡単に画像を生成することができるようになりました。これにより、だれでも手軽にイメージを画像化することが可能になります。
早速、試してみました。
1.簡単な操作性
現在、有料サブスクリプションであるChatGPT PlusやEnterpriseプランのユーザーが、この新機能ChatGPT×DALL-3が使用可能です。(※2023年10月18日現在)携帯アプリ版でも利用可能。
GPT-4を選択すると、DALL-3があります。それを選択するだけで使用可能です。
あとは、ChatGPTでテキストを入力するだけでDALL-E 3が忠実にそれをビジュアル化してくれます。
「コミュニケーションロボットのイラスト風の画像」と入力してみました。
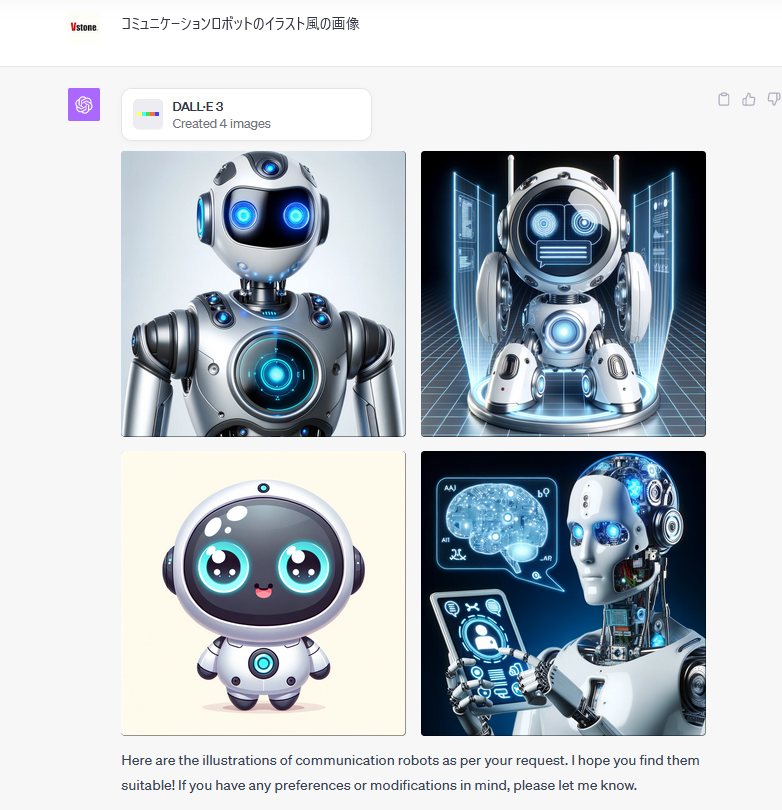
近未来的なロボットの画像から、イラスト風のものまでいろいろと4枚生成されました。
さらに、左下の3番目も画像に少し変化を加えてもらおうかと思います。「ポップな感じ」と指定してみす。
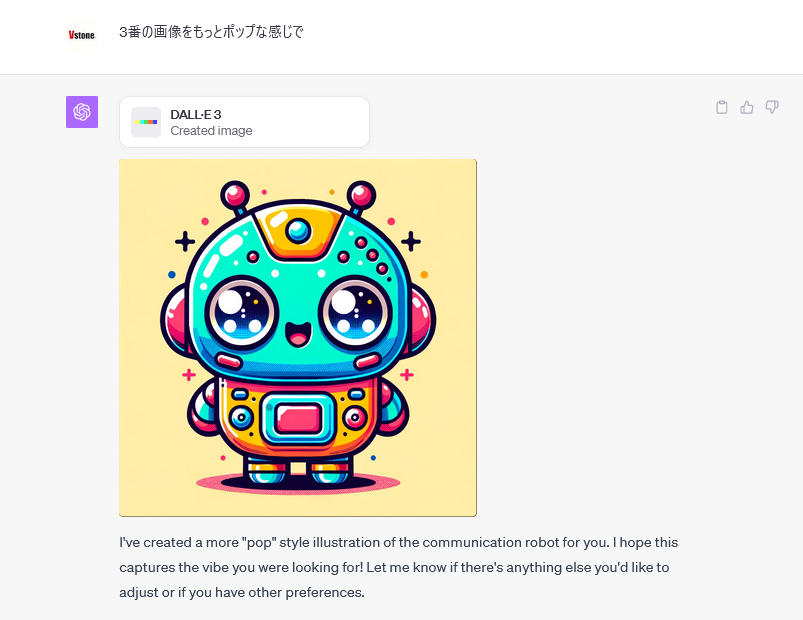
どうでしょうか。白とブルーを基調とした画像からカラフルでポップな画像に変更されました。
2.日本語対応と著作権フリー
今回の新機能アップデートのメリットとして、まず初めに日本語にも対応しているという点があげられます。MidjourneyやFireflyでは、英語でプロンプトを入力して画像を生成させるのに対し、日本語でテキスト入力するだけで簡単に画像を生成することができます。
さらに、生成された画像は著作権フリーであるため、商業的なコンテンツ制作にも利用可能な点でも、とても使いやすいものだと思います。
3.画像に文字を入れられる
どうやら、文字も入れた画像も生成できるということで、「VSTONE」という文字入れて、ロボットの会社のイメージで画像を生成してもらったのがこちら↓↓

なにやら、ロゴっぽいものが出来上がりました。
画像部分にカーソルを持っていくと、左上にダウンロードのボタンが表示されるので、そこをクリックするだけでダウンロードが可能です。
さらに、画像部分をクリックすると、右側に自動生成されたプロンプトを確認することもできます。

4.結論
ChatGPTとDALL-E 3の統合は、文字から画像へというかなり画期的なツールだと思います。この技術は、アイディアをビジュアル化するプロセスを劇的に効率化し、新しい表現の可能性となるでしょう。
今回、色々と作成試していたのですが、まだまだ思うような画像が生成できず難しいところもありますが、これからのコンテンツ制作には欠かせないツールになると思いました。
※ちなみにこのブログのキャプション画像もChatGPT×DALL-3で作成したものです。





