GPT-4 Visionの画像認識機能と、DALL-3の画像生成機能を連携させることで、写真からイラスト生成を自動化できるとおもしろいなと思い、試してみました。
1.GPT-4 VisionでSotaの画像を描写する
GPT-4を選んで、その中のDefaultを選択します。
すると、下のプロンプト入力部分に画像をアップロードできるところが表示されます

この部分から画像をアップロードします。
画像生成AIが画像を生成できるように詳しく具体的に描写してもらうように依頼します
すると、結果


2.ChatGPT×DALL-3で画像生成
次に、別のチャットを立ち上げて、GPT-4からDALL-3を選択。
GPT-4 Visionで生成された描写内容を送ります。

すると、、、
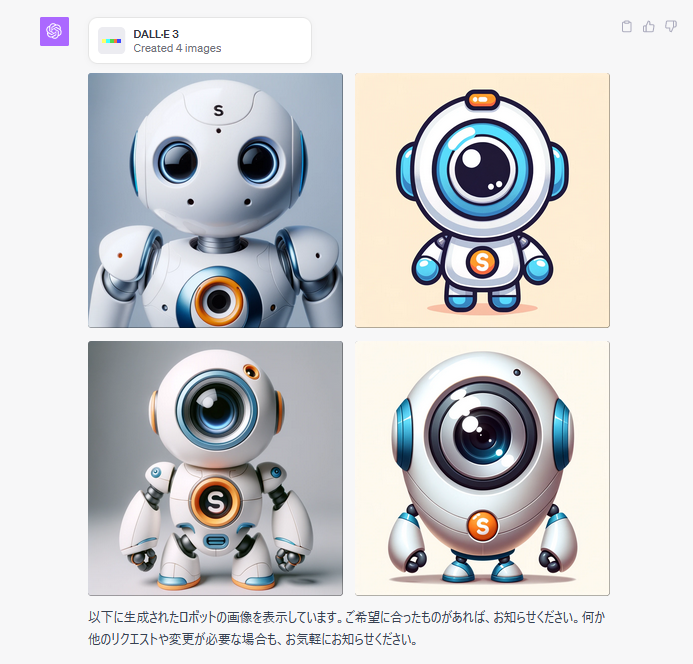
うーーーーん。どうでしょうか。。
ちょっと違うような。。。1番目のロボットが一番それっぽいですが。。
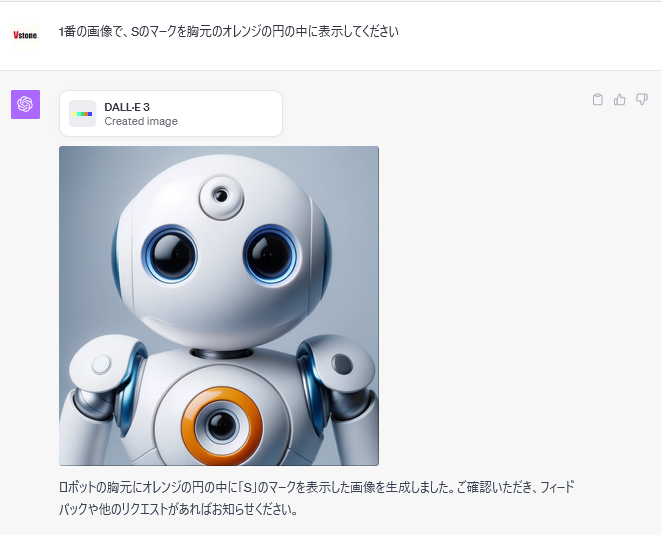
Sのマークを表示してくれませんね。。。
このあと、最終的にはイラスト化したかったので、この画像をイラスト化してもらったり、2番の画像から手直しを試したりなど、色々と試行錯誤してみたのですが、なぜか頻繁に目がひとつに表現されてしまいました。
最終的には、こんな感じ、、、

なかなか難しいです。。。
結果、Sotaくんのイラストからは遠ざかってしまうイラストばかり生成されてしまいました。
3.おまけ
試しに、かまってひろちゃんで試してみたのがこちら↓↓


うーん。顔がないので、後ろ向きを表現されてしまいますね。。。
少し手直しをして、

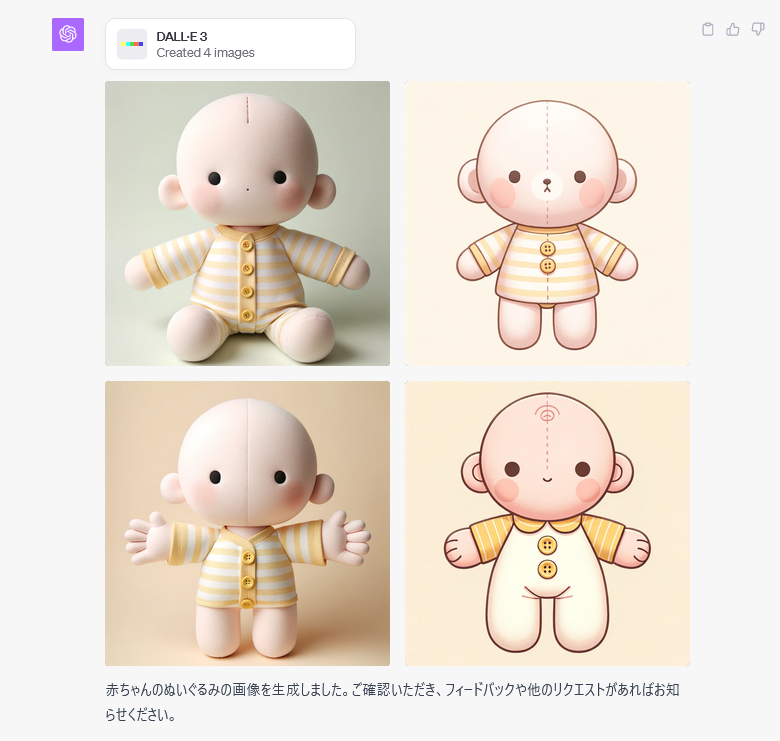
おおお!これはSotaの時に比べるとちょっと近い気がします!!
かまってひろちゃんはお顔がないぬいぐるみタイプのロボットなので、そこのところを修正してもらうプロンプトを送ってみると、

そして、それをさらにイラスト化してもらうと、

こんな感じになりました。
どうでしょうか。何度かプロンプトを送り修正していくうちに、目と鼻口が表現されてしまうこともありましたが、最終的にはいい感じに出来上がったのではないでしょうか
4.まとめ
GPT-4 Visionは、画像認識と解析に優れているのに対し、DALL-3はテキストのプロンプトからイラストを生成することができます。これらを連携させることで、画像をテキスト化し、そのテキストを基にイラストを生成してみると面白いのではと思い、試してみましたが、うまくできるときもあれば、そうでもないときもあり、、、
プロンプトなどを研究し、うまく活用できるようになれば今後業務を行う上で、なかなか便利なツールとなるのではないかなと思いました。